
| 作成日 | 2017/4/26 |
|---|
はじめに
本シリーズについて
本シリーズは、Hinemosは聞いたことはあるけど、何ができるの?どうすれば使えるの?という人を対象に、Hinemosのセットアップから基本的な利用方法について記載しています。
本シリーズのドキュメント通りに進めていただくことで、Hinemosに触れたことがない人でも、Hinemosを使いこなす最初の一歩を踏み出していただける内容になっています。
Hinemosとは?という方は、まずはこちらをご覧ください。
前回の入門編①Hinemosを使ってみようでは、Hinemosのセットアップ手順と操作方法について解説しました。今回の入門編②Hinemosで監視してみようはHinemosで監視を行うための設定と監視結果の確認について、解説していきます。2つの代表例を通して、Hinemosの監視機能の動作や使用感をつかんで頂きたいと思います。
前提
本ドキュメントで利用する環境は、入門編①で構築した環境を前提としています。
注意事項
本ドキュメントに登場するHinemos本体のバージョン番号(6.0.*)はご利用のバージョンに適宜読み替えてください。
免責事項
本ソフトウェアの使用・本ドキュメントに従った操作により生じたいかなる損害に対しても、 弊社は一切の責任を負いません。
システム構成と基本セットアップ
入門編①で構築したマネージャと対象ノードを利用します。IPアドレスなど、システム構成の詳細については、前回の『本ドキュメントで構築するシステム構成』をご参照ください。また、作成したノードとスコープも前回の環境をそのまま利用しますので、用語、または作成方法がわからない場合は、前回の『2. 管理対象の登録』と『3. スコープの作成』をご確認ください。
Hinemosで監視してみよう
入門編①ではPING監視について紹介しました。ここでは、その他の監視機能として、システムリソースの監視には欠かせないリソース監視、障害検知には欠かせないシステムログ監視を紹介します。実際に監視設定の登録を通して、Hinemosで監視するまでの流れを掴んでいきましょう。
I. リソース監視
これから紹介するリソース監視は、監視対象ノードから取得した各リソースの使用状況 (数値)を基に閾値判定を行い、監視結果(通知)を出力します。なお、監視できるリソースの種類は以下のとおりです。
- ◆CPU(使用率[%]、ロードアベレージ[個/s]など)
- ◆メモリ(使用率[%]、スワップ[kB/s] など)
- ◆ディスク(I/O回数[回/s], I/O量[byte/s]など)
- ◆ファイルシステム(使用率[%])
- ◆ネットワーク(パケット数[個/s]、情報量[byte/s] など)
まずは、CPU、ファイルシステムとネットワークの設定をそれぞれ一つずつ作成していきましょう。
設定手順
[root] # echo “view systemview included .1.3.6.1” >> /etc/snmp/snmpd.conf
[root] # cat /etc/snmp/snmpd.conf
…
# Further Information
#
# See the snmpd.conf manual page, and the output of "snmpd -H".
view systemview included .1.3.6.1
設定を反映するために、rootユーザで以下のコマンドを実行し、SNMPエージェントを再起動します。
[root]# service snmpd restart
Redirecting to /bin/systemctl restart snmpd.service

- ◆Hinemosエージェントをインストールする場合は、SNMPエージェントの設定もインストーラで行うため、手動で設定する必要はありません。
- ◆/etc/snmp/snmpd.confが見つからない場合、SNMPエージェントがインストールされていない可能性があります。インストールされていない場合、以下のコマンドを実行し、SNMPエージェントをインストールしてください。
[root]# yum install net-snmp net-snmp-utils
2. Hinemosクライアントを起動し、「監視設定」パースペクティブを開きます。
↓クリックすると画像が拡大されます↓
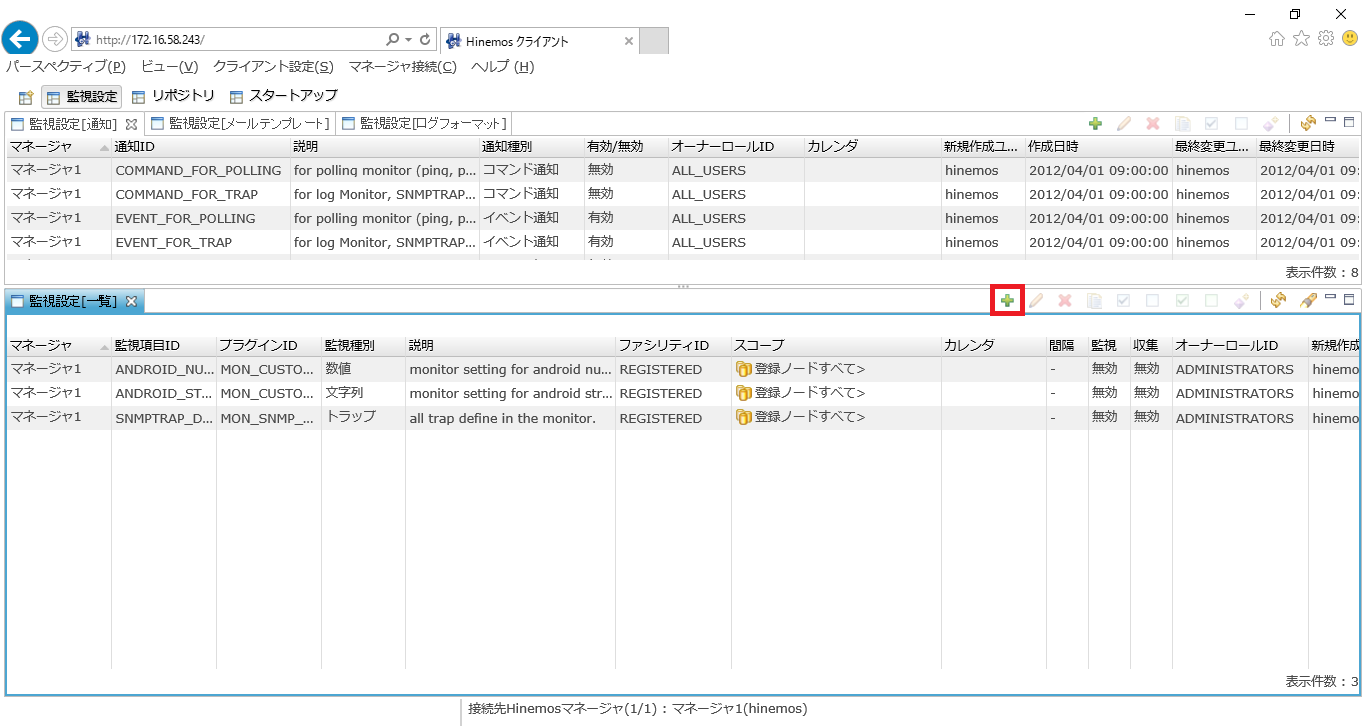
3. 「監視設定[一覧]」ビューの右上にある「作成」ボタンをクリックします。
4. 「監視種別」ダイアログから「リソース監視 (数値)」を選択し、「次へ」をクリックします。そして、作成・変更ダイアログが表示されます。
↓クリックすると画像が拡大されます↓
5. 「リソース[作成・変更]」ダイアログでは、入力必須項目は背景色がピンク色で表示されます。以下のように、「監視項目ID」、「スコープ」などの必須項目を入力し、「判定」の取得値と通知を設定します。なお、通知方法はデフォルトの「STATUS_FOR_POLLING」を選択します。
↓クリックすると画像が拡大されます↓
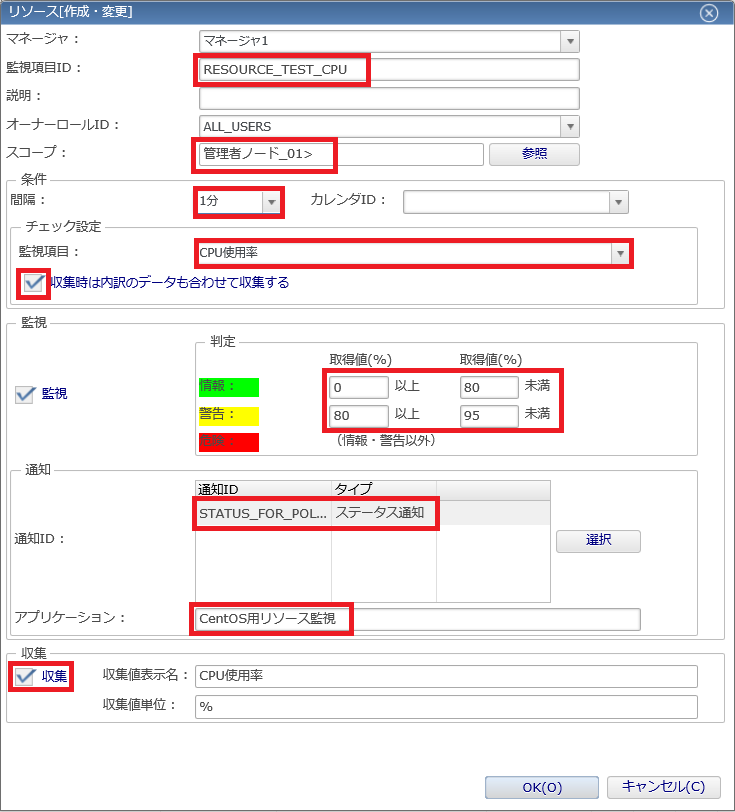
- ◆「収集」をチェックした場合、数値監視の結果を蓄積し、グラフ表示またはCSVファイルに出力することができます。
- ◆「収集時は内訳のデータも合わせて収集する」のチェックを入れた場合、内訳を持つ項目(例えば、CPU使用率の内訳としてユーザやシステムが占める割合など)は、『収集』をチェックした場合にその内訳の項目も合わせて収集します。
6. これでCPU使用率の監視設定は完了です。監視設定が登録されたことと、監視と収集が有効になっていることを「監視設定[一覧]」ビューにて確認してください。
↓クリックすると画像が拡大されます↓

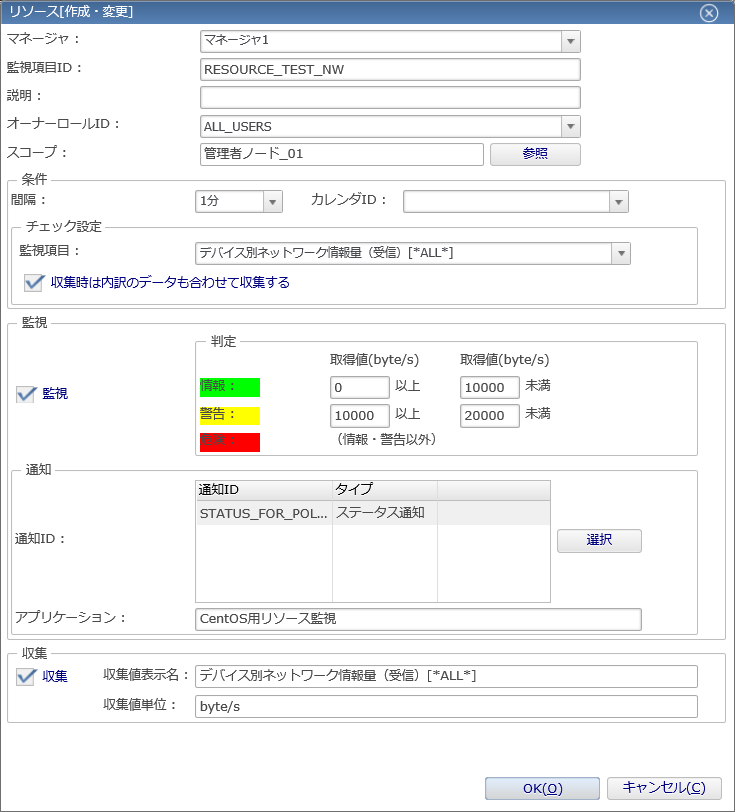
7. 続いて、CPU使用率と同様にファイルシステム使用率とネットワーク情報量の監視設定を追加してみましょう。
↓クリックすると画像が拡大されます↓

以上でリソース監視の設定は完了です。
- ◆今回は動作確認用として、短期間で結果が確認できるように監視間隔を1分と設定しましたが、大量に監視設定を行った場合のHinemosマネージャへの負荷を考慮し、5分以上の値を設定することを推奨しています。実際に使用する場合は、運用要件にあわせ適切に設定してください。
監視結果の確認
続いて、設定したリソース監視の結果を見てみましょう。
1. 「監視」パースペクティブをメニューバーから開きます。
↓クリックすると画像が拡大されます↓
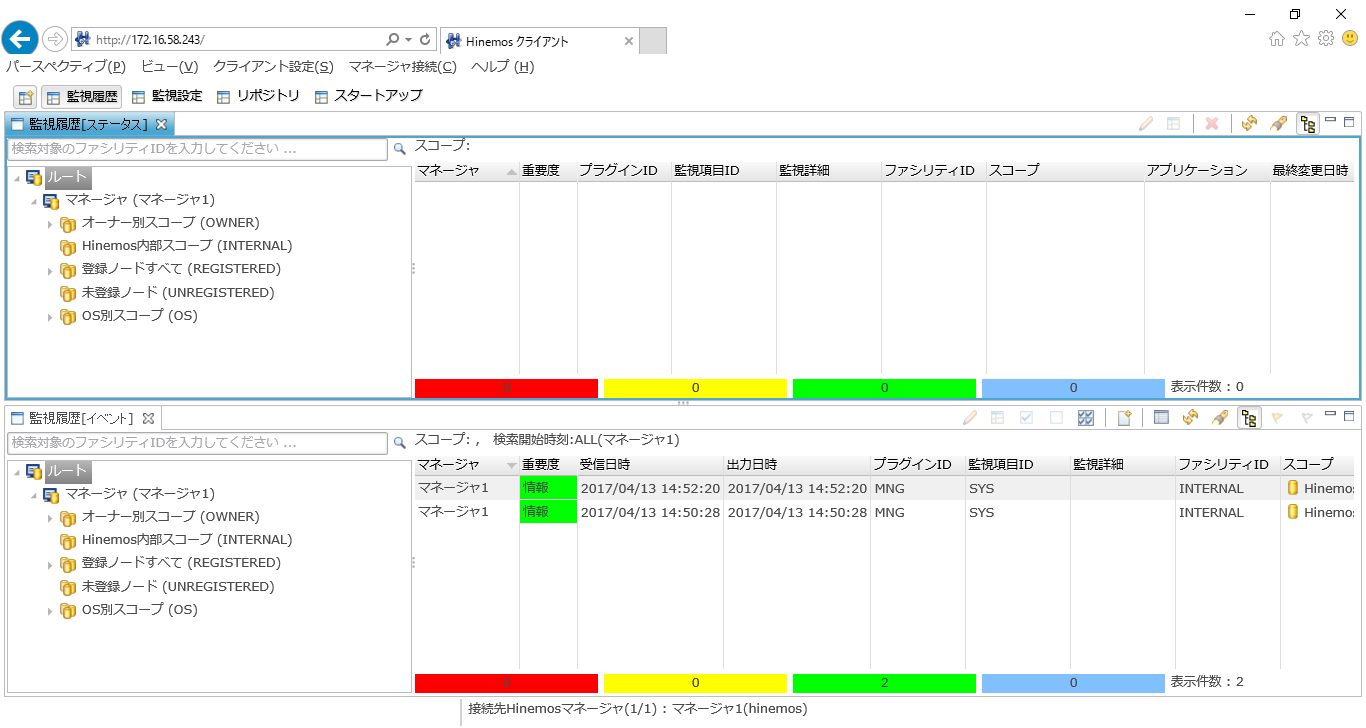
2. 管理対象ノードで特に処理が行われていない場合は、負荷が低く設定した閾値を超えないため通知は発生しません。そのため、監視対象ノードの負荷を上げ、検知されるような事象を意図的に発生させてみましょう
- ◆CPU使用率で故意に上げる方法
yesコマンドでCPU負荷を上げることができます。以下のコマンドを2、3分実行し続けて、Ctrl-Cで止めます。
[root] # yes >> /dev/null
- ◆ファイルシステム使用率を故意に上げる方法
大きいサイズのファイルを作成することで、ファイルシステムの空き容量を減らすことができます。以下の例では、10GBのダミーファイルを作成します。作成するファイルのサイズは実際の環境にあわせて調整してください。
[root] # cd /tmp
[root] # dd if=/dev/zero of=bigtempfile bs=1M count=10000
- ◆ネットワーク情報量を故意に上げる方法
ファイルをダウンロード、またはアップロードすることで、ネットワーク情報量の値を上げることができます。以下の例では、「ファイルシステム使用率を故意に上げる方法」にて作成したファイルを、マネージャサーバに転送します。
[root] # cd /tmp
[root] # scp /tmp/bigtempfile root@172.16.58.243:/tmp/
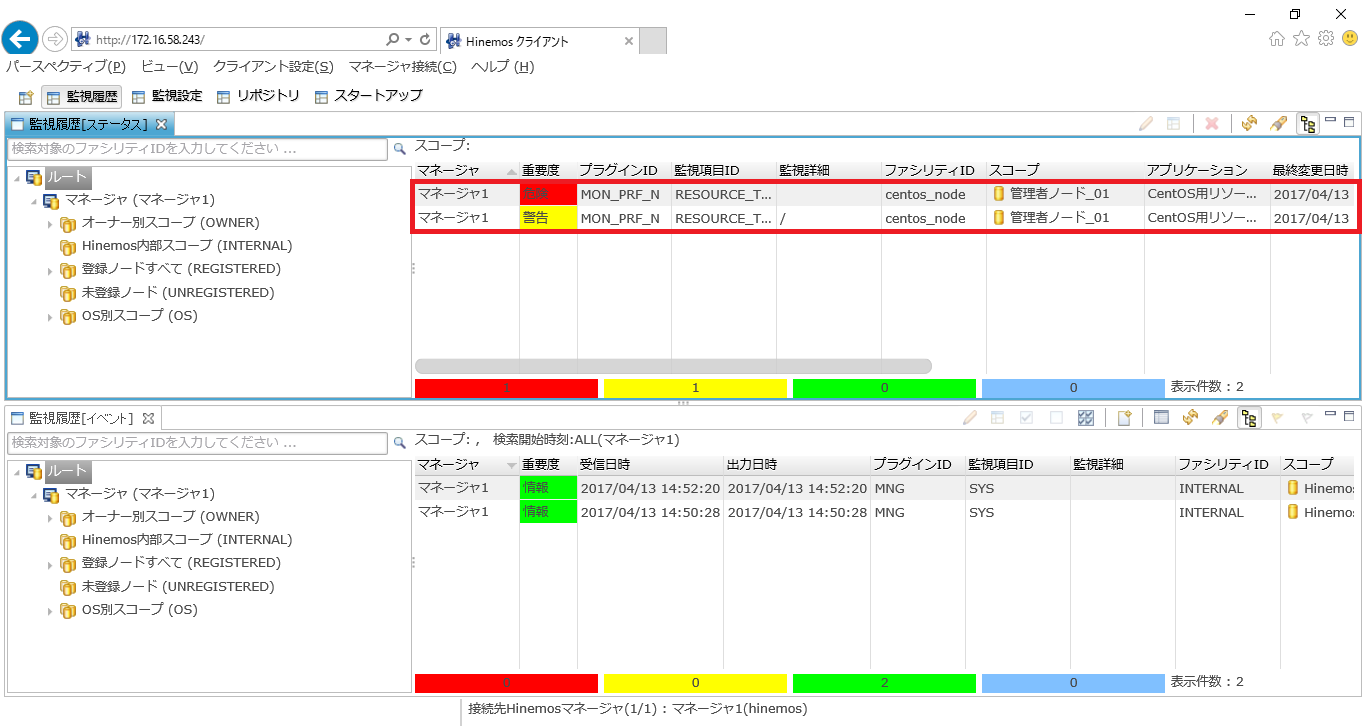
3. 次に「監視[ステータス] 」ビューのツールバーにある「更新」ボタンをクリックし、意図的に上げた負荷が検知されているかを確認します。
下記の例では、CPU使用率とファイルシステム使用率が設定した閾値を超えたため、検知されていることが確認できます。
↓クリックすると画像が拡大されます↓
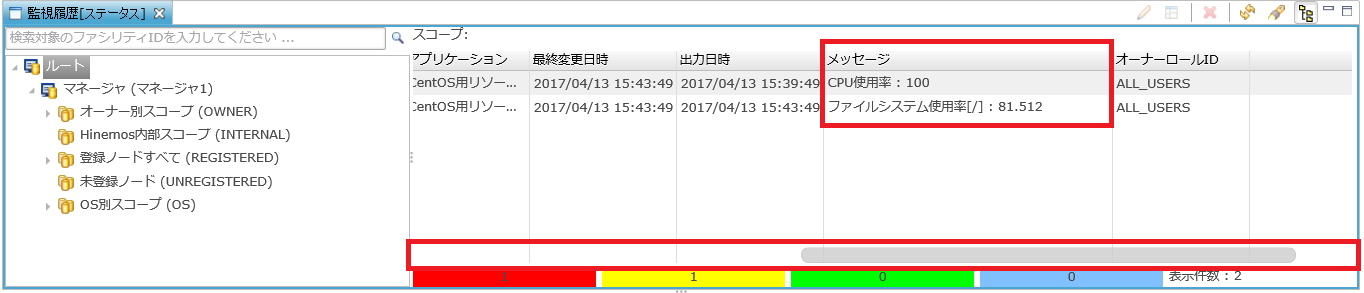
さらに、「監視[ステータス] 」ビューの画面を右側にスクロールすると、メッセージ列にて実際の収集値が確認できます。
↓クリックすると画像が拡大されます↓
- ◆「 監視[ステータス]」ビューはデフォルトで10分おきで更新されます。即時更新したい場合は、ツールバー上の「更新」ボタンを押してください。
収集結果の確認
Hinemosの性能機能を使用すれば、数値監視の収集値をグラフ表示、またはファイル出力することができます。
次の手順で、収集した値をグラフで確認してみましょう。
1. まず、グラフ表示で監視結果を確認します。メニューバーから「性能」パースペクティブを開きます。
↓クリックすると画像が拡大されます↓
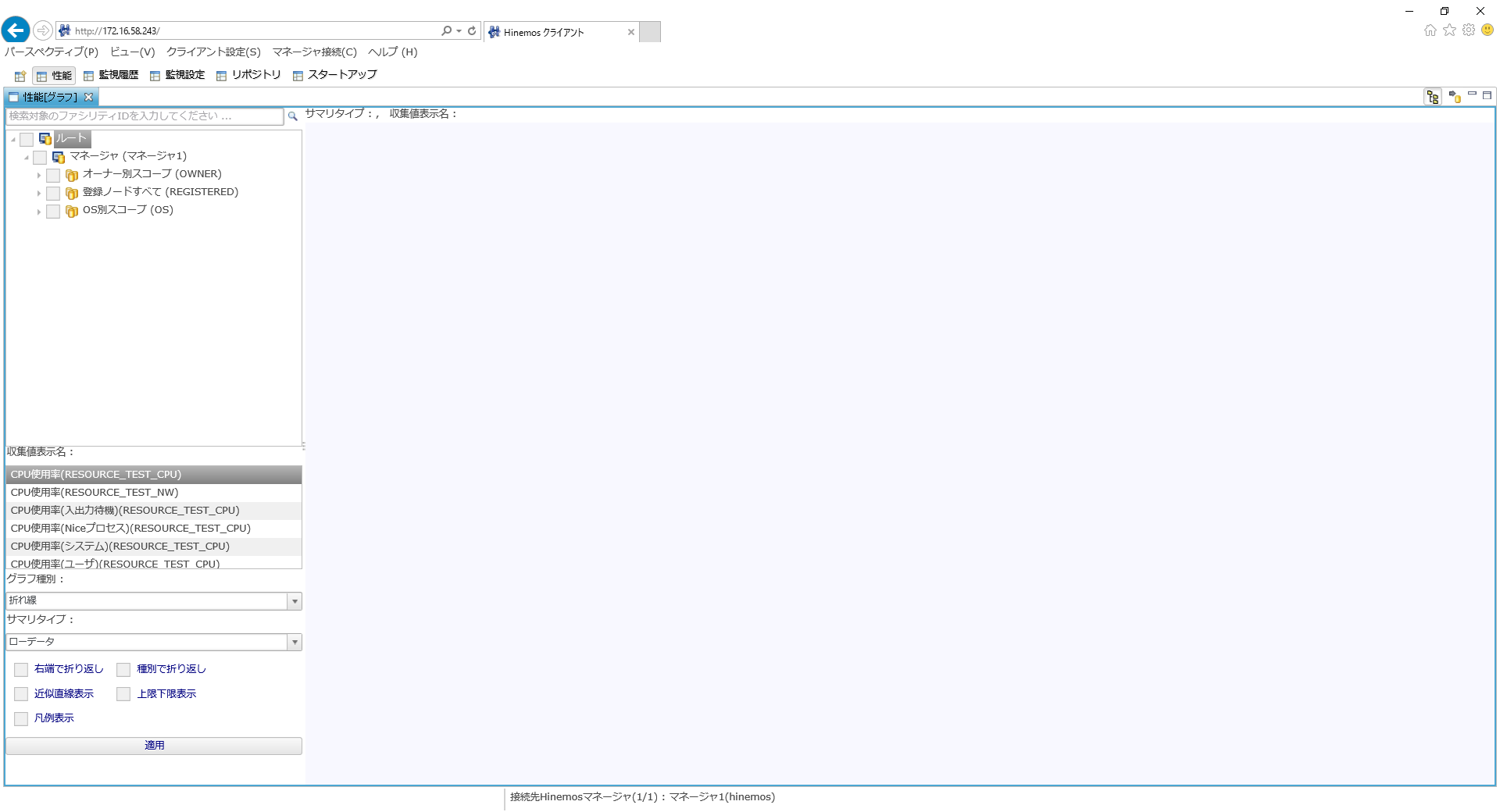
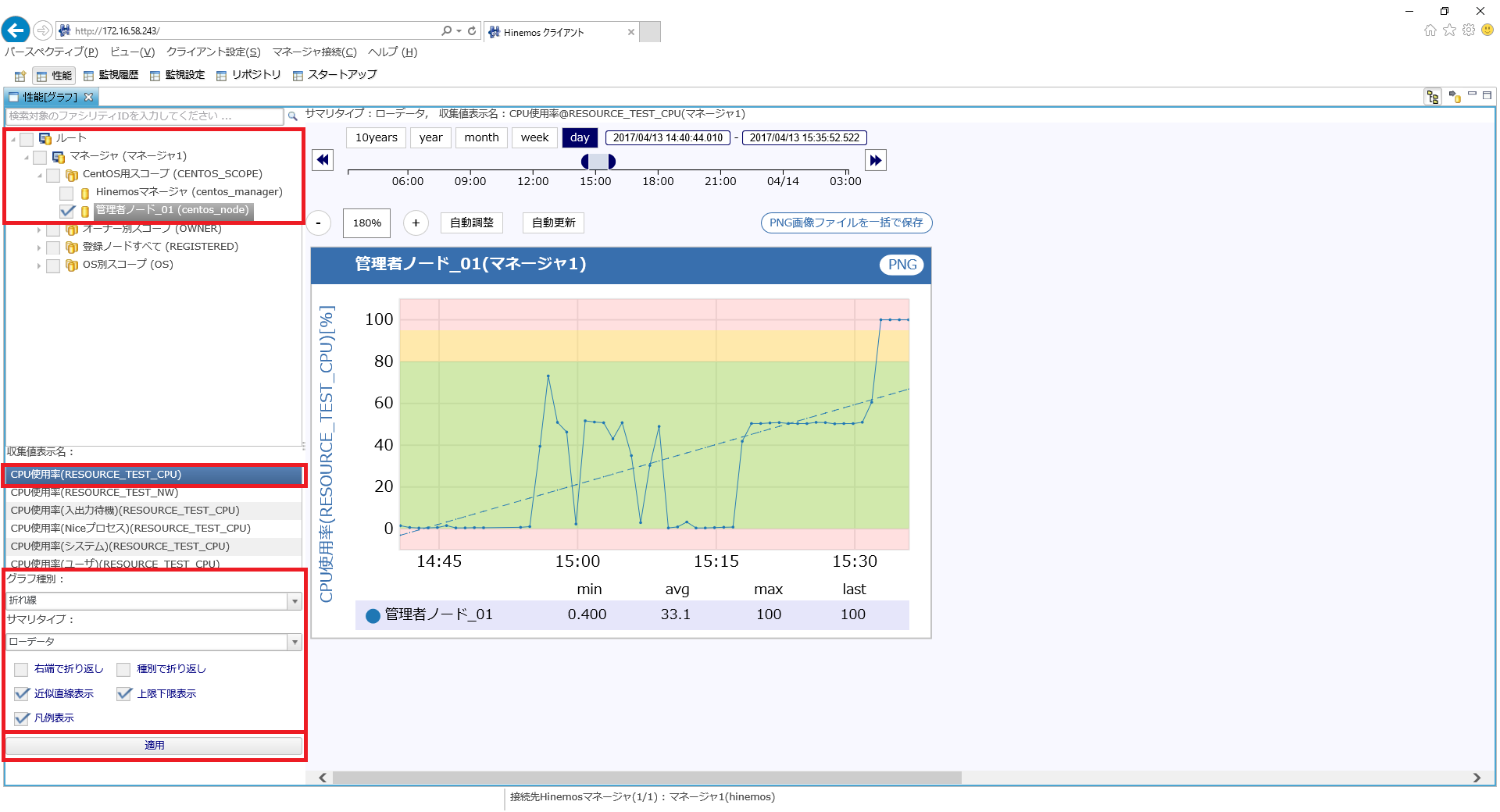
2. 「性能[グラフ]」ビュー上の「ルート>マネージャ(マネージャ1)>CentOS用スコープ(CENTOS_SCOPE)>管理者ノード_01(centos_node)」を選択します。収集表示名に「CPU使用率(RESOURCE_TEST_CPU)」を選択し、以下のように、グラフ種別などの項目を設定します。「性能[グラフ]」ビュー最下部の「適用」ボタンをクリックすると、グラフ上でCPUリソースの利用状況をグラフで確認できます。
↓クリックすると画像が拡大されます↓
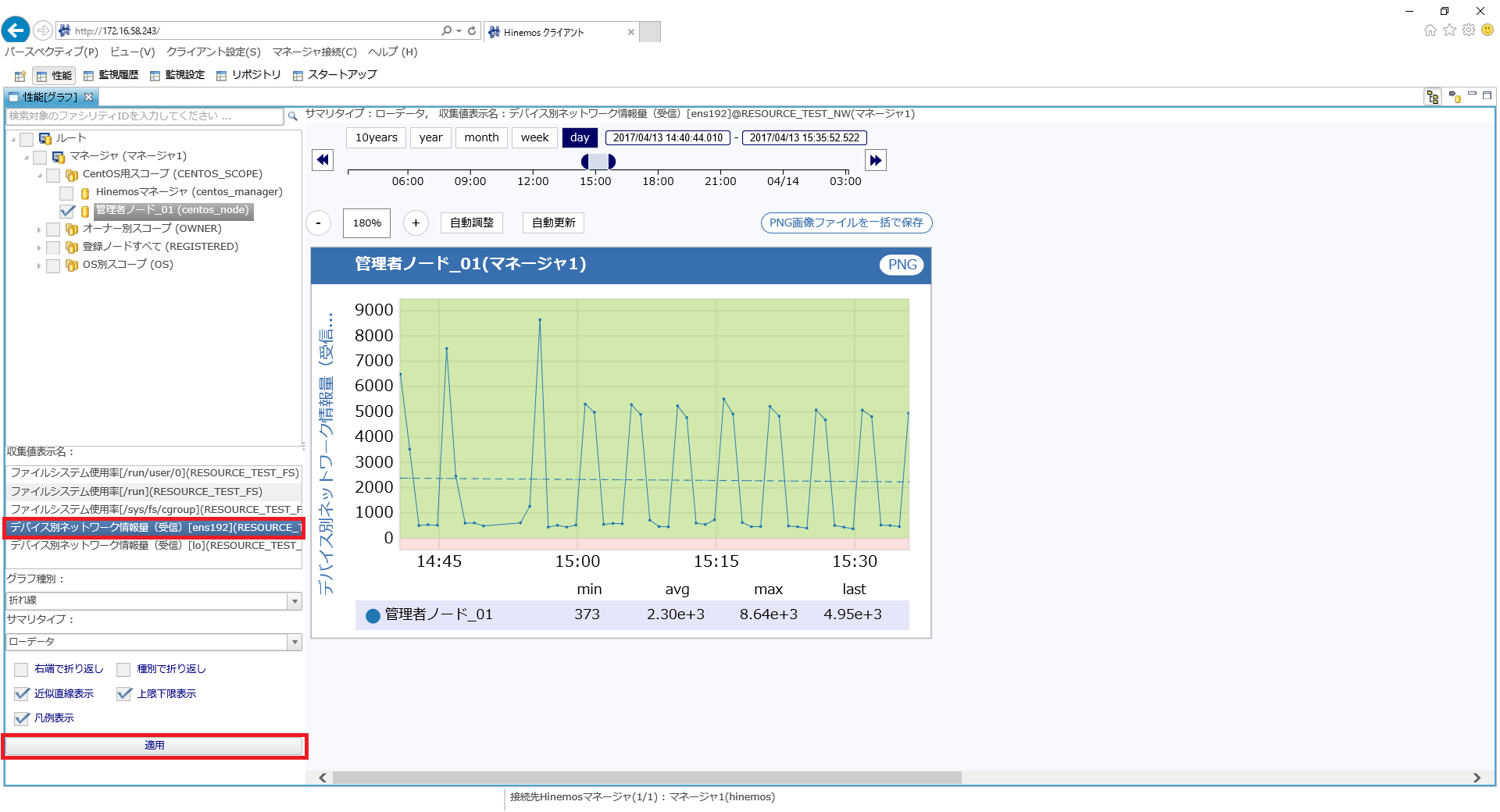
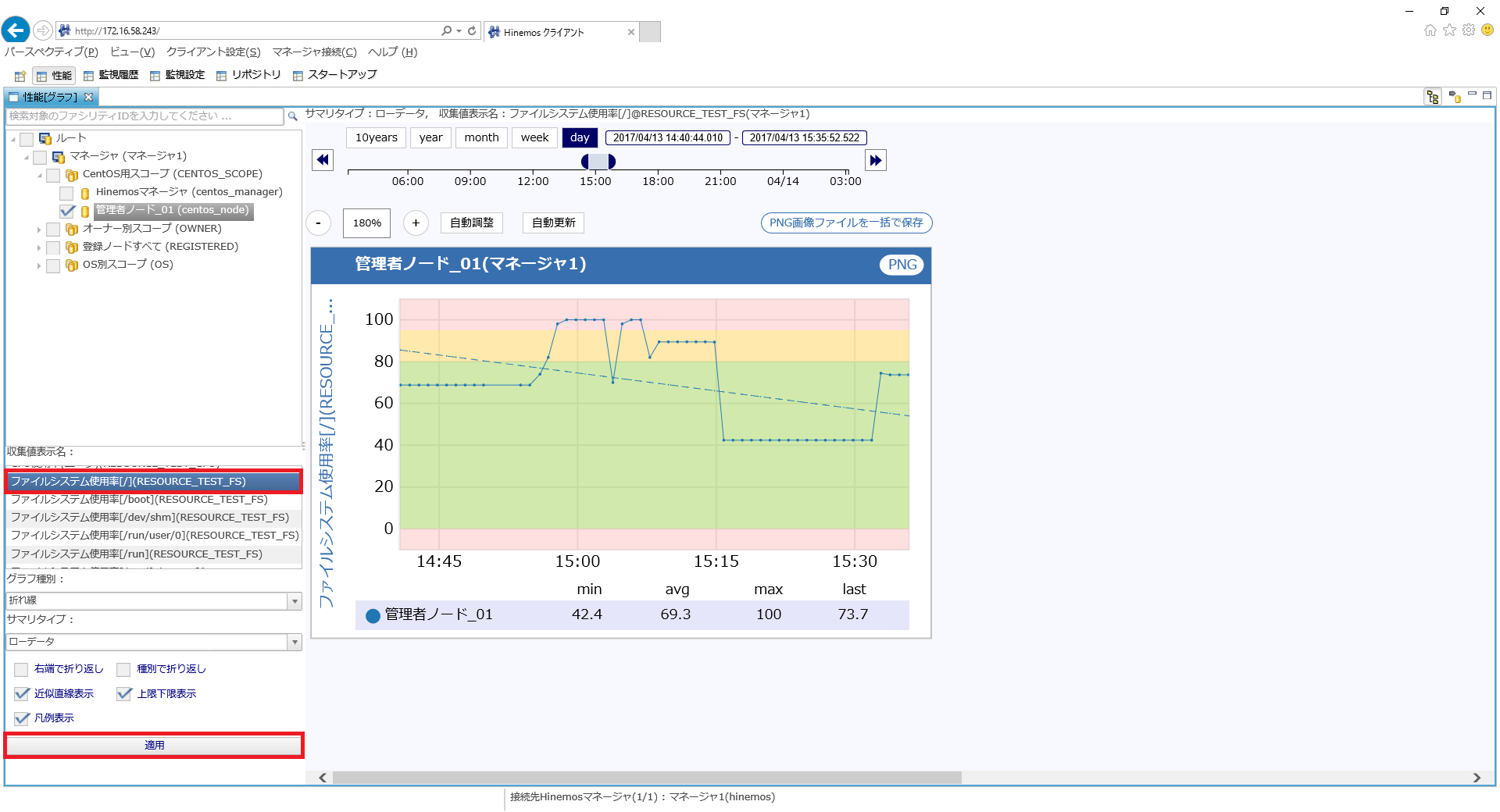
「RESOURCE_TEST_FS」と「RESOURCE_TEST_NW」も「RESOURCE_TEST_CPU」と同様に、表示してみてください。
↓クリックすると画像が拡大されます↓
- ◆「性能[グラフ]」ビューのツールバー上の「CSVエクスポート」ボタンをクリックすると、収集した値をCSV 形式でダウンロードできます
- ◆グラフ右上の「PNG」ボタンをクリックすると、表示しているグラフをPNG形式でダウンロードできます
II. システムログ監視
次に文字列監視であるシステムログ監視について紹介していきます。
Hinemosのシステムログ監視は、管理対象ノードのシステムログに出力されたログに対して文字列のフィルタ処理を行い、あらかじめ設定しておいた特定の文字列にマッチした場合に通知を行います。
では、実際にシステムログ監視を設定してみましょう。
設定手順
1. システムログ監視はrsyslogdを利用するため、管理対象ノード側で、設定ファイル/etc/rsyslog.confの最後に“*.info;mail.none;authpriv.none;cron.none @@172.16.58.243:514”とHinemosマネージャへログを転送する設定を追加します(172.16.58.243はHinemosマネージャのIPアドレスです)。
[root]# echo “*.info;mail.none;authpriv.none;cron.none @@172.26.58.243:514” >> /etc/rsyslog.conf
[root]# cat /etc/rsyslog.conf
...
# remote host is: name/ip:port, e.g. 192.168.0.1:514, port optional
#*.* @@remote-host:514
# ### end of the forwarding rule ###
*.info;mail.none;authpriv.none;cron.none @@172.16.58.243:514
rsyslogdを再起動し、設定変更を反映します。
[root]# service rsyslog restart
- ◆Hinemosエージェントをインストールする場合、rsyslogの設定もインストーラで行うため、上記のrsyslog.confの設定は必要ありません。
2. Hinemosクライアントを起動し、「監視設定」パースペクティブを開きます。
↓クリックすると画像が拡大されます↓
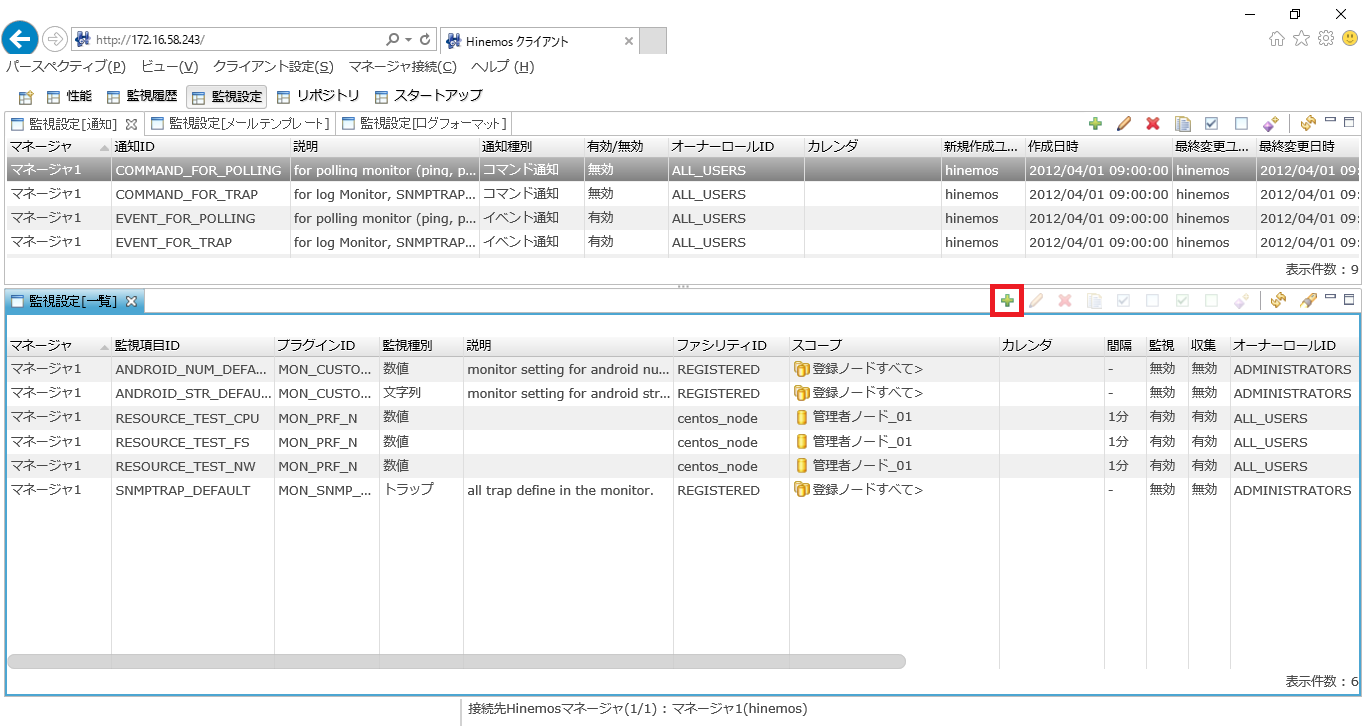
3. 「監視設定[一覧]」ビューの右上にある「作成」ボタンをクリックします。
4. 「監視種別」ダイアログから「システムログ監視 (文字列)」を選択し、「次へ」をクリックします。
↓クリックすると画像が拡大されます↓
5. 表示された「システムログ[作成・変更]」ダイアログでは、入力必須項目は背景色がピンク色で表示されます。以下のように、「監視項目ID」、「スコープ」などの必須項目と「判定」条件を設定します。また、通知方法はデフォルトの「EVENT_FOR_POLLING」(イベント通知)を選択します。
↓クリックすると画像が拡大されます↓
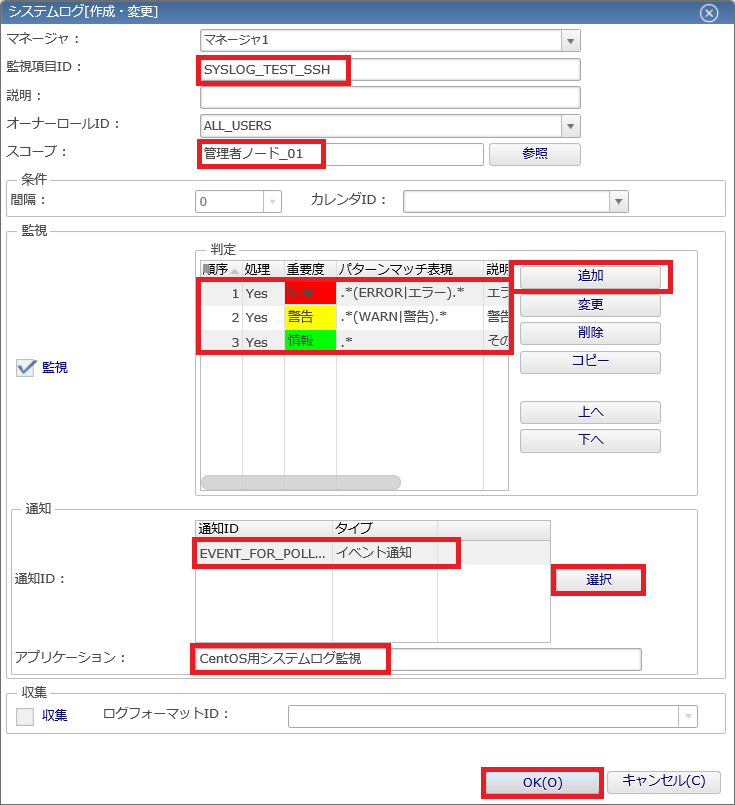
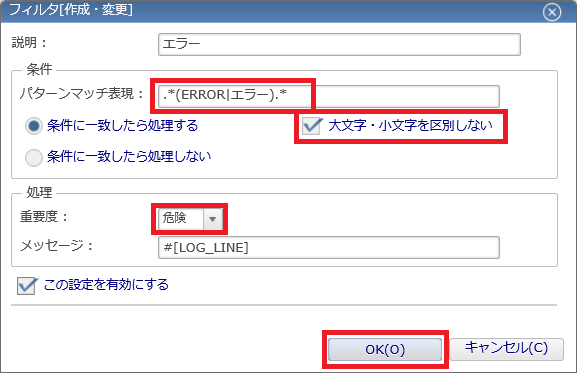
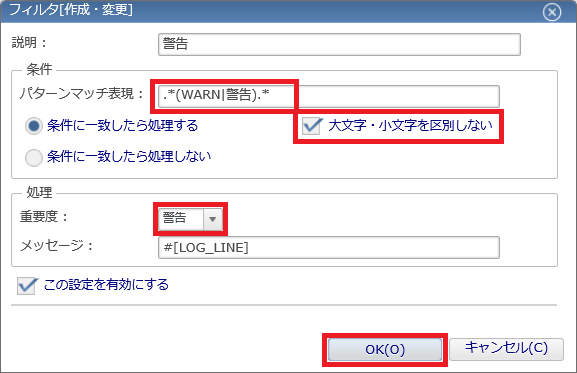
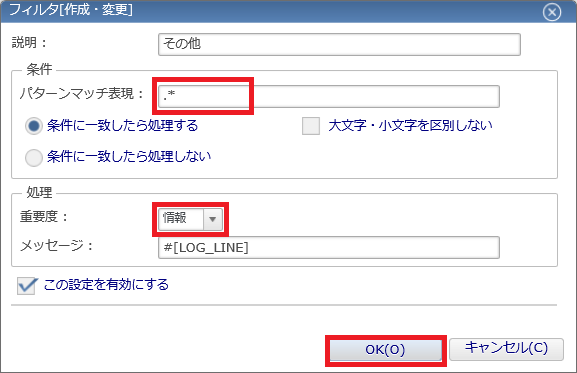
- ◆リソース監視はステータス通知を利用しましたが、システムログ監視はイベント通知を利用します。ステータス通知は、監視結果の最新状態のみ必要な場合に利用する通知機能です。一方、イベント通知は、監視結果を現在の状態だけでなく、過去の情報も含めて保存し、履歴として確認したい場合に利用します。そのため、リソース監視は最新の状態を確認できるステータス通知を利用し、システムログ監視はすべてのログ履歴を確認できるイベント通知を利用しています。
- ◆判定の順番については順序が若い順に判定され、パターンマッチ表現に合致したら、それ以降の条件は確認されません。判定条件の順番を変えたい場合は、対象のパターンマッチ表現を選択し、「上へ」ボタンと「下へ」ボタンを押すことで入れ替えることができます。
以上で、システムログ監視の設定は完了です。
監視結果の確認
次に、システムログ監視の結果を見ていきましょう。
1. 「監視」パースペクティブ開きます。
2. ログを出力します。監視対象ノード上で、以下のコマンドを実行し、rsyslogにログを出力します。
[root]# logger "問題ありません"
[root]# logger "ERROR: エラーが発生しました"
3. 「監視[イベント]」ビューで右上のツールバーにある「更新」ボタンをクリックし、緑色の重要度:情報のイベントと赤色の重要度:危険のイベントが表示されることを確認します。
↓クリックすると画像が拡大されます↓
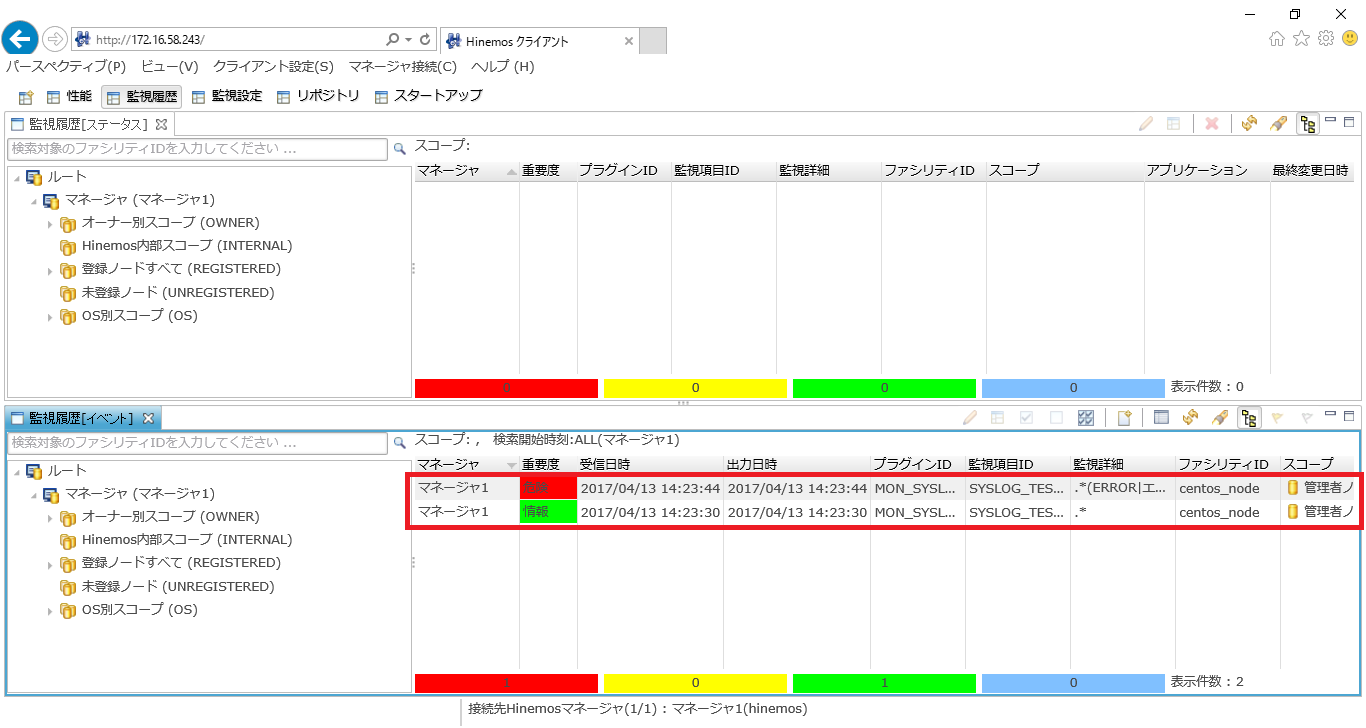
最後に、検知したログの内容を確認します。詳細を確認したいイベントを選択し、 ダブルクリックまたは『詳細』ボタンをクリックすると、「監視[イベントの詳細]」ダイアログが開きます。
さらに、「監視[イベントの詳細] 」ダイアログの「オリジナルメッセージ」欄を選択すると、右端に“・・・”ボタンが表示されますので、クリックしてください。
↓クリックすると画像が拡大されます↓

「オリジナルメッセージ」ダイアログが開き、検知したログの内容が確認できます。
- ◆Apache のログファイル(/var/log/httpd/*)のように、任意の場所のログファイルを監視したい場合は、ログファイル監視を使用してください。ただし、ログファイル監視はHinemosエージェントを介して検知したログをHinemosマネージャに転送するため、Hinemosエージェントのインストールが必要となります。Hinemosエージェントの導入は次回の『Hinemos ver.6.0 入門編③ Hinemos ver.6.0でジョブを動かしてみよう』で解説します。
デフォルトのEVENT_FOR_TRAP設定では、30分以内に同じ重要度の通知は、1回のみ行われるようになっています。すべて通知したい場合は、EVENT_FOR_TRAPの設定に「常に通知する」を指定してください。
その他の監視機能
本編は、リソース監視、システムログ監視の設定と結果の確認を行いましたが、Hinemosはこの他にも様々な目的に対応できるように、全16種類の監視機能を提供しています。そのうちの12種類は Hinemosエージェントのインストールすることなく、エージェントレスで利用可能です。
| 監視機能 | 概要 | エージェントレスでの利用 |
|---|---|---|
|
・汎用的なIPネットワーク機器の死活/状態監視 |
||
| PING監視 (数値) |
対象機器へのping応答の有無により死活状態を監視します。 |
○ |
| SNMPTRAP監視 (トラップ) |
対象機器からSNMPTRAPを受信することで、対象機器の状態を把握します。 |
○ |
|
・プロダクトやプロセスの死活/状態監視 |
||
| Hinemosエージェント監視 (真偽値) |
Hinemosエージェントの死活状態を監視します。 |
× |
| HTTP監視 (数値/文字列/シナリオ) |
Webサーバの応答有無や応答時間、HTTPレスポンスの内容から状態を監視します。また、あらかじめ設定したシナリオ通りにWebサーバにアクセスし、期待した結果が得られるか監視します。 |
○ |
| SQL監視 (数値/文字列) |
DBサーバの応答有無、SQLレスポンスの内容から状態を監視します。 |
○ |
| プロセス監視 (数値) |
起動しているプロセス数から状態を監視します。 |
○ |
| Windowsサービス監視 (真偽値) |
Windowsサービスの状態を監視します。 |
○ |
| サービス・ポート監視 (数値) |
特定のサービス・ポートについて、応答有無や応答時間から状態を監視します。 |
○ |
| JMX監視 (数値) |
Javaアプリケーションの状態を監視します。 |
○ |
|
・各種機器のリソース状況の監視 |
||
| リソース監視 (数値) |
対象機器のリソース情報を取得してその状態を監視します。 |
○ |
|
・ログメッセージの監視 |
||
| システムログ監視 (文字列) |
各種OSのシステムログに出力されたメッセージを監視します。 |
○ |
| ログファイル監視 (文字列) |
特定のログファイルに出力されたメッセージを監視します。 |
× |
| Windowsイベント監視 (文字列) |
Windowsイベントログに出力されたメッセージを監視します。 |
× |
|
・汎用的/拡張可能な監視機能 |
||
| SNMP監視 (数値/文字列) |
汎用的なプロトコルSNMPの応答の内容を監視します。 |
○ |
| カスタム監視 (数値/文字列) |
ユーザ定義のコマンド/スクリプトの実行結果を監視します。 |
× |
| カスタムトラップ監視 (数値/文字列) |
json形式のリクエストを受信し、その内容を監視します。 |
○ |
- ★Hinemosの監視機能は、内容に応じて次の5つのカテゴリに分類されています。
| カテゴリ | 概要 |
|---|---|
| 数値 |
監視対象が数値になります。この対象の数値について閾値判定を行い通知します。例えば、本編で紹介したリソース監視が相当します。 |
| 文字列 |
監視対象が文字列になります。監視対象から取得した、または送信されてきた文字列に対して、パターンマッチ文字列を定義したフィルタ設定でフィルタリングを行い、 合致したフィルタ条件に指定された通知設定で通知をします。例えば、本編で紹介したシステムログ監視が相当します。 |
| 真偽値 |
監視対象の状態がOKかNGかを監視し、それぞれの状態に指定された通知設定で通知をします。例えば、Hinemosエージェント監視が相当します。 |
| トラップ |
本カテゴリは、SNMPTRAP監視のみ該当します。受信したSNMPTRAPについて、マッチするOIDがあれば、通知します。 |
| シナリオ |
本カテゴリは、HTTP監視のみ該当します。単一のURLではなく、複数のURLに順番にアクセスすることにより、 監視対象に想定されるアクセスが行なわれた際に正しく応答を返せるかを監視します。各URLにアクセスした際のステータスコードおよびHTTPレスポンスの内容にマッチすれば、通知します。 |
最後に
入門編②では、リソース監視、システムログ監視をピックアップしてご紹介しました。本編をとおして、Hinemos監視機能について操作方法と結果の確認方法を掴んでいただけたと思います。リソース監視、システムログ監視以外にも多くの監視機能がありますので、ぜひご利用の環境に合わせて、試してみてください。
次の入門編③では、Hinemosのジョブ機能についてご紹介します。
Hinemosのスタートアップ情報関連
関連情報
Hinemos ver.4.1の[実践]入門の本が販売中です。内容はHinemos ver.4.1ですが、Hinemosをより詳しく知りたい方には、お勧めの一冊です。

お問い合わせ
