Hinemos ミッションクリティカルオプションとは
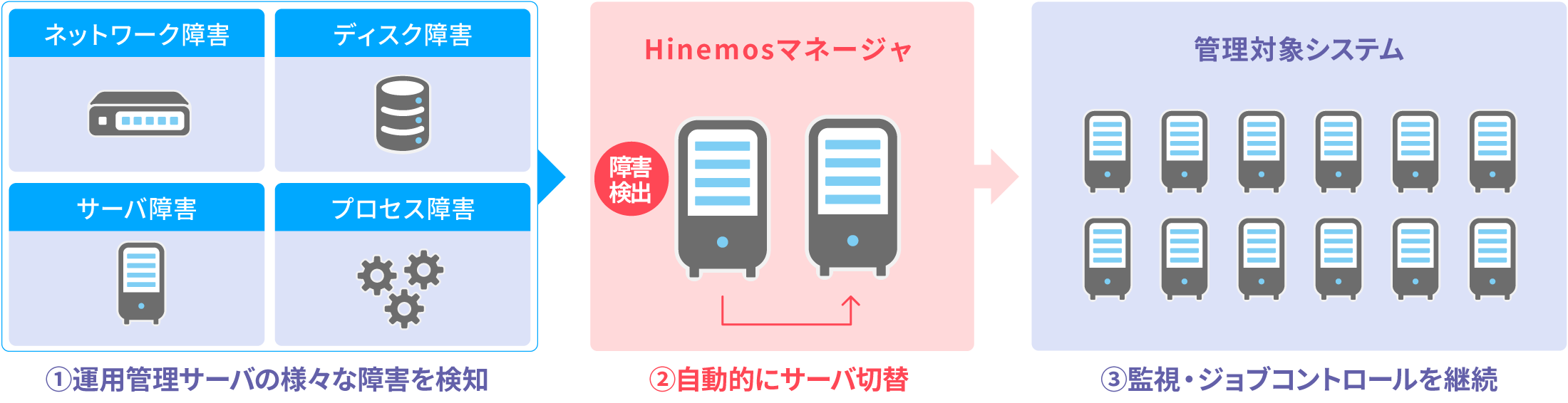
ミッションクリティカルシステムの無停止運用を、Hinemos自身の冗長化により強力にサポートします。運用管理サーバのHW障害など様々な異常を自動検出し、スタンバイサーバへの系切替など必要な対処を自動実行します。これにより、監視、ジョブといった運用管理の継続実行を実現します。
特徴
-
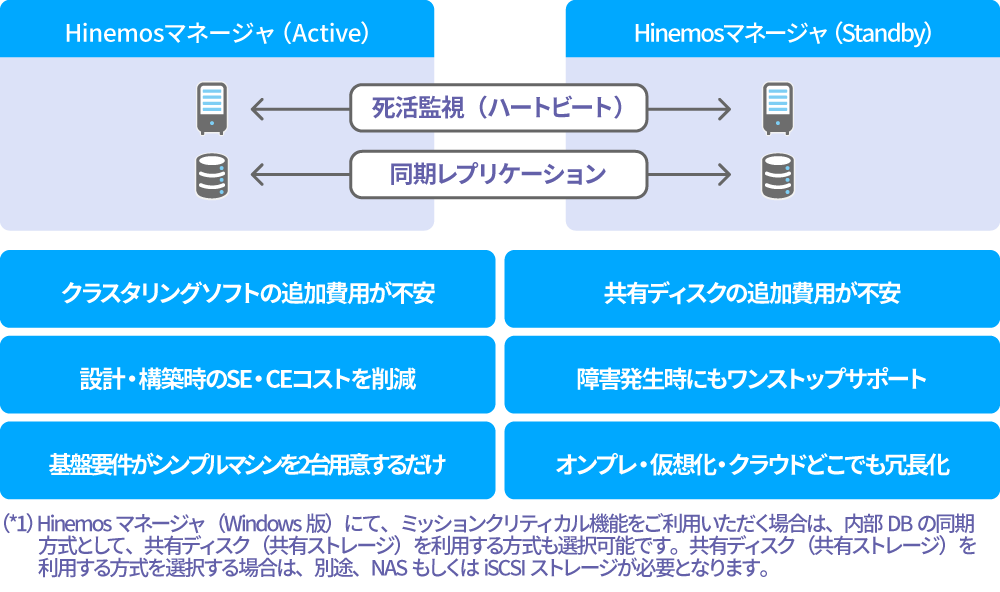
クラスタリングソフトや共有ディスクは不要
高価なクラスタリングソフト・共有ディスク(*1)の準備は不要です。ミッションクリティカル機能は、Hinemosマネージャの動作環境が2サーバ分あれば、利用可能です。冗長化の仕組みがHinemos製品の中で完結するため、複雑な組み合わせの検討・検証作業無しで利用可能であり、設計・導入も容易です。万が一障害が発生した場合も、Hinemos製品としてワンストップでのご対応が可能です。
-
オンプレ・仮想化・クラウドどこでも利用可能
Hinemosミッションクリティカル機能は、オンプレミス・仮想化・クラウド環境において、全て同一のアーキテクチャで可用性構成を実現します。オンプレミス環境ではIAサーバを2台、仮想化環境ではハイパーバイザが異なる仮想マシンを2台、クラウド環境ではインスタンスを2台用意するだけで、同じスキルセットで、Hinemosのミッションクリティカル機能を導入可能です。

-
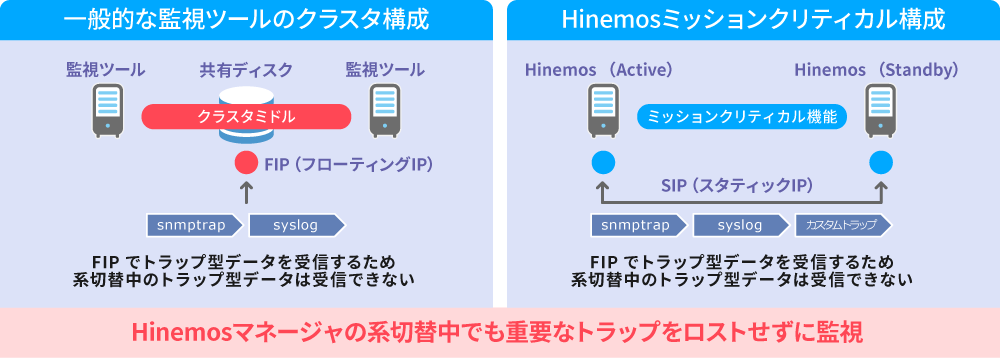
ロスト無しの監視・ジョブ継続を実現
系切替が発生した場合においても、監視対象機器から送信されるsyslog、 SNMPTRAPを取りこぼすことなく、監視を継続することが可能です。他社製のクラスタリングソフトに依存せず、Hinemos製品として冗長化機能を完備しているため、無停止での監視運用を、複雑な製品組み合わせ方式検討無く実現可能です。
-
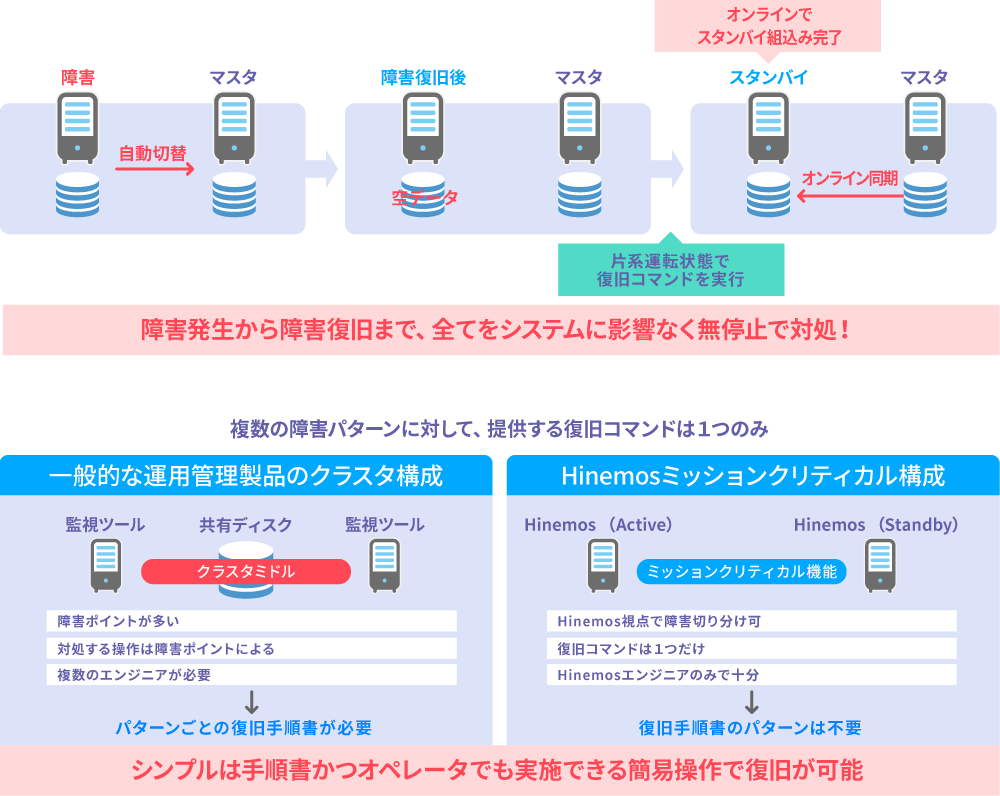
オンラインでの障害復旧が可能
Hinemosマネージャサーバに障害が発生し、片系運転となった場合も、障害原因を取り除くことで、運用管理を停止することなく、オンラインで両系運転に復旧することが可能です。片系運転からの復旧は、障害パターンに応じて準備されている復旧手順・コマンドを実行することで、実現可能です。