
| 作成日 | 2019/12/24 |
|---|---|
| 更新日 | 2024/05/28 |
概要
クラウド利用もスタンダードになってきた昨今でも、運用管理製品のクラウド上の可用性構成は非常に大きな課題です。
本技術情報は、クラウド環境上で可用性構成の難しさとその解決方法を解説します。それにより、先日AWS
東京リージョンで発生したようなAZの大規模障害時でも安心して運用継続できることを説明します。
クラウド上の運用管理マネージャを高可用性構成にするには?
AWSやAzureといったパブリッククラウド上で、運用管理のマネージャの可用性構成を組むには、クリアすべき3つの課題があります。
この課題を1つ1つ見ていきます。
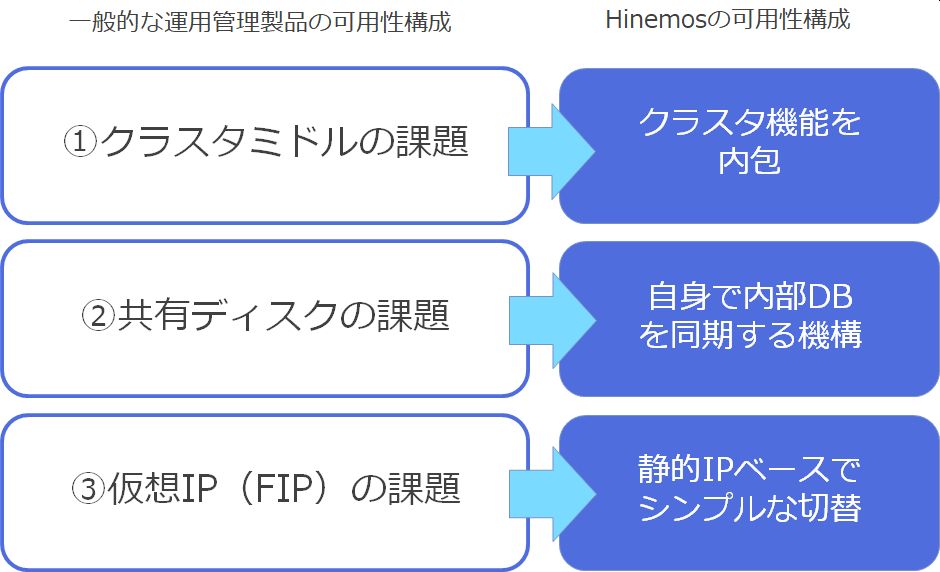
①クラスタミドルの課題
-
◆一般的な運用管理製品
運用管理製品に限らず、一般的な可用性構成と言えば、次の特長があります。
- - クラスタミドルウェアがサーバやミドルウェアの死活を管理
- - 共有ディスクにマスター・スレーブで共有するデータを配置
- - 仮想IP(VIP,FIP)を制御して外部からのリクエストを受け付ける
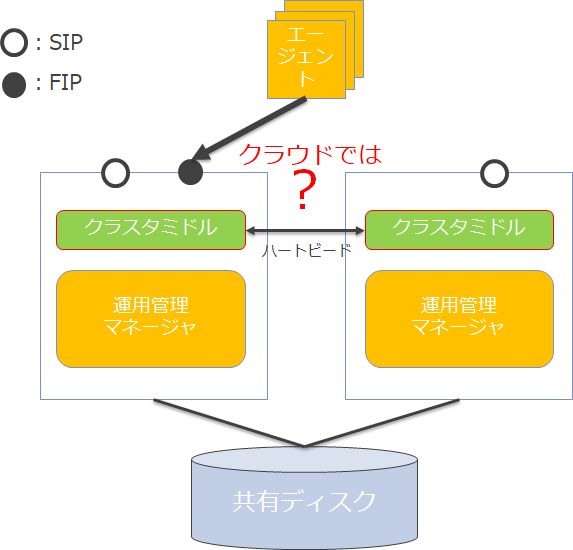
オンプレミス環境、仮想化環境では当然な構成でも、パブリッククラウド環境では当然ではありません。その課題を順に見ていきます。
最初に課題に上がるのは、クラスタミドルウェアをどうするか、というものです。具体的には以下の課題があります。-
課題1:クラスタミドルはクラウド上でサポートされるか?
クラウド上で稼働させたい運用管理ソフトウェアだけでなく
- ●クラスタミドル自体が対象のクラウド上で動作するか
- ●クラスタミドルが対象のクラウド上での運用管理ソフトウェアとの組み合わせで動作サポートがあるか
といった点を確認する必要があります。
-
課題2:クラスタミドルは目的の障害に対応できるか?
オンプレミス環境では、サーバ筐体やNW機器といった障害が主でした。しかし、パブリッククラウドでは、対象のクラスタミドルが
- ●NWセグメント障害(VPC等)に対応しているか?
- ●データセンタ障害(AZ等)に対応しているか?
といった事も確認が必要です。
-
◆Hinemosマネージャの可用性構成(Linux版マネージャの場合)
Hinemosの場合、ミッションクリティカル機能を使う事で、これらの課題を解決します。
まず、MC機能はクラスタミドルウェア相当の機能を内包しています。これにより、Hinemosの障害を外部のクラスタミドルを導入することなく正確に検知します。もちろん当該機能はNWセグメント障害、データセンタ障害にも対応します。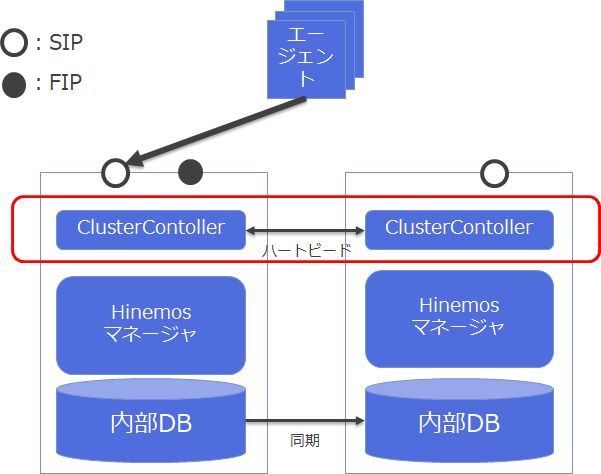
②共有ディスクの課題
-
◆一般的な運用管理製品
続いて、クラスタミドル同様に、パブリッククラウド上では共有ディスクにも課題があります。
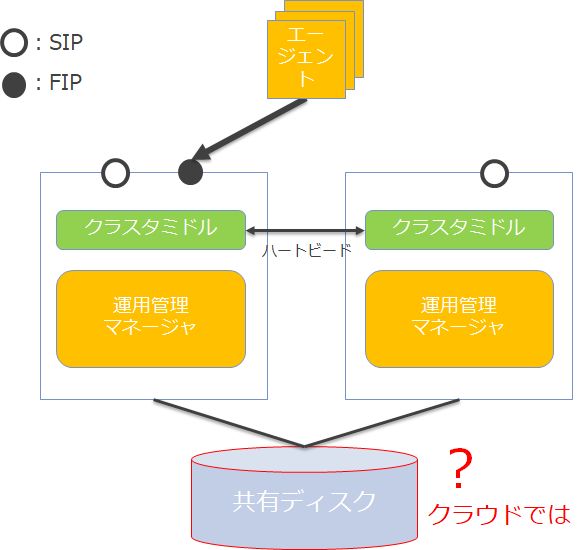
-
課題1:共有ディスクには何を代替にするのか?
クラウドサービスにより、様々なサービスが用意されています。また共有するデータの形式は製品より異なるため、どれが適したサービスなのかを判断する必要があります。例えば、
- ●ブロックストレージ(EBS等)を使った方が良いのか?
- ●DBサービス(RDS等)を使った方が良いのか?
といった選択肢があります。各サービスを利用する際の料金も気にする必要があります。
-
課題2:共有ディスクの代替は目的の障害に対応できるか?
データの形式だけではなく、採用するサービスが目的の障害に対応しているかもしっかりと確認する必要があります。例えば、
- ●NWセグメント障害は(VPC等)? ⇒ NWセグメントを跨いで共有できるか
- ●データセンタ障害は(AZ等)? ⇒ データセンタを跨いで共有できるか
といった事も確認が必要です。
-
-
◆Hinemosマネージャの可用性構成(Linux版マネージャの場合)
Hinemosの場合、ミッションクリティカル機能を使う事で、これらの課題を解決します。
まず、MC機能は共有ディスクを使用することなく、自分自身でデータの同期を行います。もちろんNWセグメント障害、データセンタ障害にも対応します。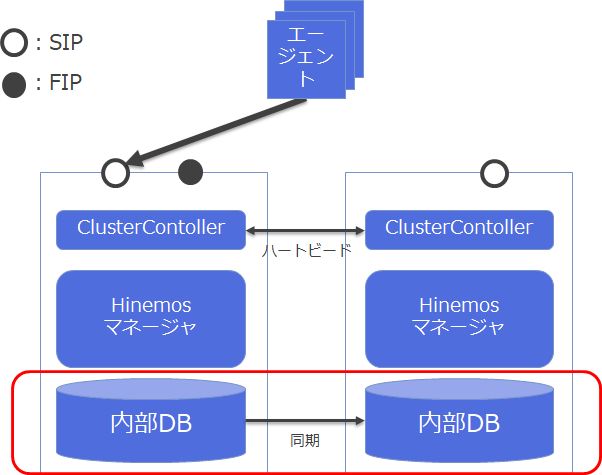
③仮想IP(FIP)の課題
-
◆一般的な運用管理製品
最後の課題が一番大きな問題です。パブリッククラウド上では、実は仮想IPの扱いが非常にセンシティブです。
AWSの課題:AWSにおける仮想IPが使用できない条件
AWSでは次のNW間で仮想IPへ接続できません。
- ・VPC Peer間
- ・Direct Connect間
この動作は、VPCのRouteTableはVPC内からの通信にしか効かない点にあります。そのため、運用管理のマネージャと、エージェントがこのNWを跨ぐ場合に、運用管理マネージャのFIP方式は使えないという問題が出てきます。
Azureの課題:IP関連の問題
AzureではIP関連処理で次の問題があります。
- ・IP付け替え処理が遅いAPI操作で数分レベル
例えば、Azure環境でIPアドレスの付け替えには以下のようなコマンドの処理が必要ですが、本処理に非常に時間がかかります(数分レベル)。
az network nic ip-config delete -g <リソースグループ名> -n <IP構成名> --nic-name <旧MasterサーバのNIC名> az network nic ip-config create -g <リソースグループ名> -n <IP構成名> --nic-name <新MasterサーバのNIC名> --private-ip-address <FIP>これに伴い、Azureが提示する可用性構成のベストプラクティスは、ロードバランサを使った振り分けの方式になります。そのため、クラスタ構成がクラウドサービスに依存し、またこれをユーザが自分たちでくみ上げるという作業が必要になります。
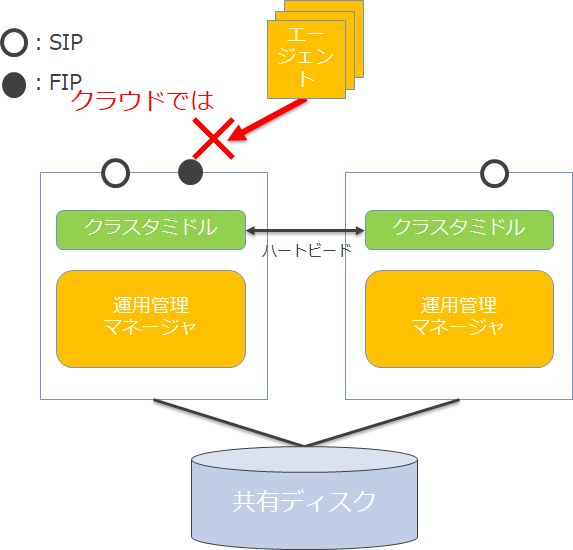
以上より、パブリッククラウド上の仮想IPは鬼門の様に、利用が難しいものになります。
-
◆Hinemosマネージャの可用性構成(Linux版マネージャの場合)
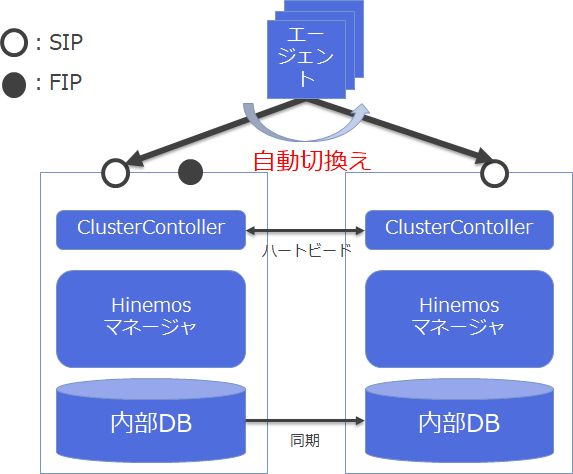
Hinemosの場合、ミッションクリティカル機能を使う事で、これらの課題を解決します。MC機能のポイントを以下に紹介します。
-
Hinemosは静的IPに対応
仮想IPにも対応していますが、静的IPのみを使用することも可能です
-
障害発生ノードから正常ノードへ自動で切替
非常にシンプルな動作です。Hinemosエージェント側に、Hinemosマネージャ(マスタ・スタンバイ)の静的IPのリストを指定することで、順次正常なHinemosマネージャを探して接続しに行きます。そのため、環境に依存することなく、どのHinemosマネージャと接続しているかも後で追いやすい仕組みです。
-
VPC間、Direct Connect間も問題なし
当たり前ですがIPリーチャブルな環境であれば、どこでも接続可能です
-
-
◆参考情報:運用管理製品が故の課題
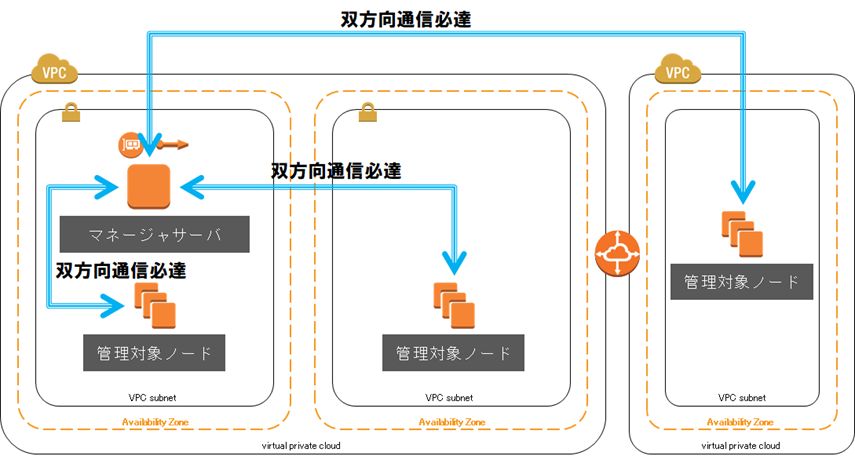
実はこの仮想IPの問題は、主に運用管理製品のような「全ノードにエージェントをインストールする構成」するソフトウェアでのみ顕在化する内容です。システムのメインで扱うアプリケーションを高可用性にするのであれば、それに適したシステムアーキテクトを選択すると思いますが、全ノードで動作するのが当たり前な運用管理製品では、検討が後回しになりますし、そもそも複雑な課題なく使えることが求められます。Hinemosはこれをシンプルなアーキテクチャで解決しています。
3つの課題のまとめ
これまでの3つの課題を纏めると次のようになります。
◆Hinemosの可用性構成のポイント
これまでの課題からHinemosのミッションクリティカル機能のポイントは次の通りになります。
- ●Hinemosというソフトウェアで可用性構成を実現
- クラスタミドルも共有ディスク不要です。
- ●可用性構成のトラブルもソフトウェアの範疇で対応
- 製品の組み合わせによる切り分けが不要になります。
- ●オンプレ・仮想化・クラウドで同じ可用性構成
- どの環境でも可用性構成は同じアーキテクチャで、VPC、DirectConnectを跨いだシステムも対応します。
- ●クラウドの仮想IP問題も意識する必要なし
- 運用管理製品特有の問題も簡単にクリアしています。
AWSの東京リージョン大規模障害
◆2019.8.23のAWSの東京リージョン大規模障害の概要
先日発生したAWSの大規模障害の概要を簡単に整理してみます。
-
規模
2019年8月23日12時30分から発生
6~10時間前後継続 -
対象
AWSの東京リージョンのAP-NORTHEAST-1で発生
EC2、EBS、RDSのサービスの一部が対象
様々な障害が報告されていますが、ポイントは大きく2点です。
-
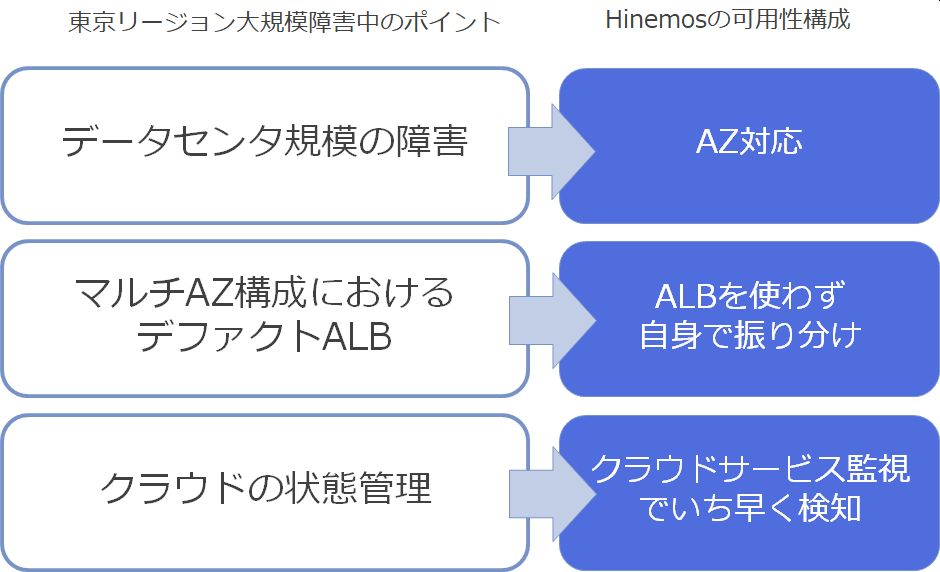
データセンタ規模の障害
東京リージョンにある3つのアベイラビリティゾーン(AZ)の1つが障害。このAZはデータセンタに該当し、この規模で発生した障害です。
-
マルチAZ構成におけるデファクトALBでもエラーが発生し回避不可
もちろんAZ障害の対応策が今までなかったわけではなく、デファクトとして採用される方式はApplication Load Balancer(ALB)を使った方式でした。しかし、このALBも実体としてはどこかのAZ上で動作するものであったため、結果としてこのALBも正常に動作しなかったという問題が報告されています。
AWSの東京リージョン大規模障害中のHinemosは?
当該時間帯のHinemosは監視・ジョブ共に運用業務を継続していました。そのポイントは次の点にあります。
クラウドサービス監視
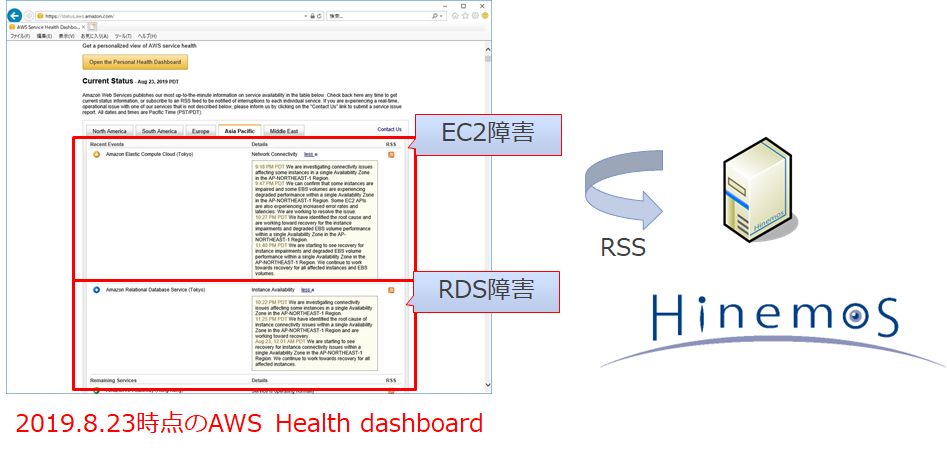
オンプレミス環境、仮想化環境ではサーバ機器などの実体が見えないため、クラウドサービスが提供しているサービスが正常かどうかを、これまでとは別な仕組みで監視する櫃湯があります。 AWS、Azure、GoogleCloud、OCIそれぞれに関して、次のようなサイトで、自身の提供するサービスの正常性を公開しており、ユーザはRSSでこの情報を取得します。そして、システムに障害があった場合、アプリケーションの問題なのか、クラウドサービスの問題なのかを切り分ける必要があります。
-
AWS Service Health Dashboard
-
Azure status
-
Google Cloud Service Health
-
OCI Status
Hinemosのクラウド管理機能を使うと、AWS Service Health Dashboardの情報を自動的に取得し、障害時にアラートを上げることができます。そのため、時系列の一連のイベントの中にクラウドのサービス提供状態が含まれることで、今回のような障害も一次切り分けを簡易に行うことができます。
まとめ
パブリッククラウド上で運用管理マネージャの可用性を構成するには数多くの課題があること、そしてHinemosではミッションクリティカル機能により簡易にこの課題を解決していることが分かったと思います。 また、先日のAWSの大規模障害においてもHinemosが監視やジョブといった重要な運用業務を継続でき、AWSの障害自体も正しく検知できることが分かったと思います。 パブリッククラウド上で止めてはいけない運用管理基盤を構築する場合は、Hinemosをご検討ください。
免責事項
本技術情報は、2019年8月時点の内容を記載したものです。記載内容に相違がある場合は、お問い合わせまでご連絡ください。
