
キーワード
- 可用性
- クラスタ
- AWS
- Azure
- 運用
- 監視
- ジョブ管理
- 自動化
- ログ管理
| 作成日 | 2023/09/01 |
|---|---|
| 更新日 | 2023/09/01 |
この記事を作成した人

概要
本記事ではHinemos自体の可用性を実現するHinemosミッションクリティカル機能に関して、パブリッククラウドであるAWS(Amazon Web Services)上に構築されたITシステムの運用管理を行う際の機能の必要性から動作まで詳しく解説していきます。
AWSにおける運用管理の冗長化の必要性
AWS上に構築するシステムに限らず可用性の実現には、DBサーバやAPサーバ、Webサーバといった中枢となる機能を思い浮かべる人が多いと思います。しかし、監視やジョブといった運用管理機能の可用性の確保できないと、サービス提供に大きな支障を与えます。特にAWSといったパブリッククラウドでは、これまでのオンプレミス環境や仮想化環境とは異なる障害への対応も必要になります。
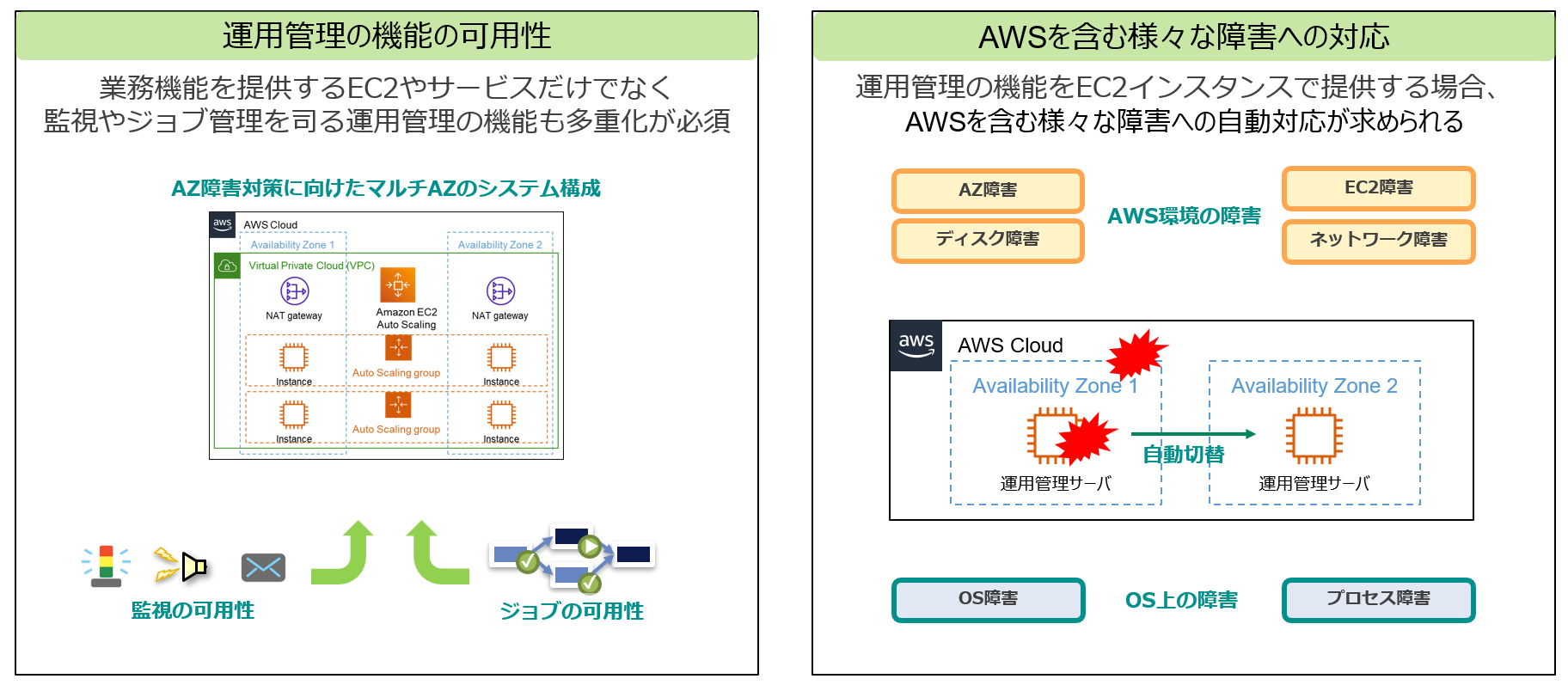
AWSにおける運用管理の冗長化の難しさ
しかしAWSなどのパブリッククラウドで運用管理機能の冗長構成を取るのは非常に難しいです。これは監視やジョブ管理を行う運用管理製品の特徴に起因します。先ほども上げたDBサーバやAPサーバ、Webサーバなどは用途や通信対象が限られるのに対し、運用管理機能はITシステム上の全てのサーバにNW的に接続を行い、監視やジョブ管理を行う必要があります。またオンプレミス環境などで実現していた古典的なクラスタ構成では、フローティングIP(仮想IP(VIP)とも言う。以降、FIPと記載)や共有ディスク、そして別途クラスタ製品の導入が必要です。
実はパブリッククラウド上ではこのようなNW通信の条件や古典的なクラスタ構成の要素の殆どが制約になってしまいます。
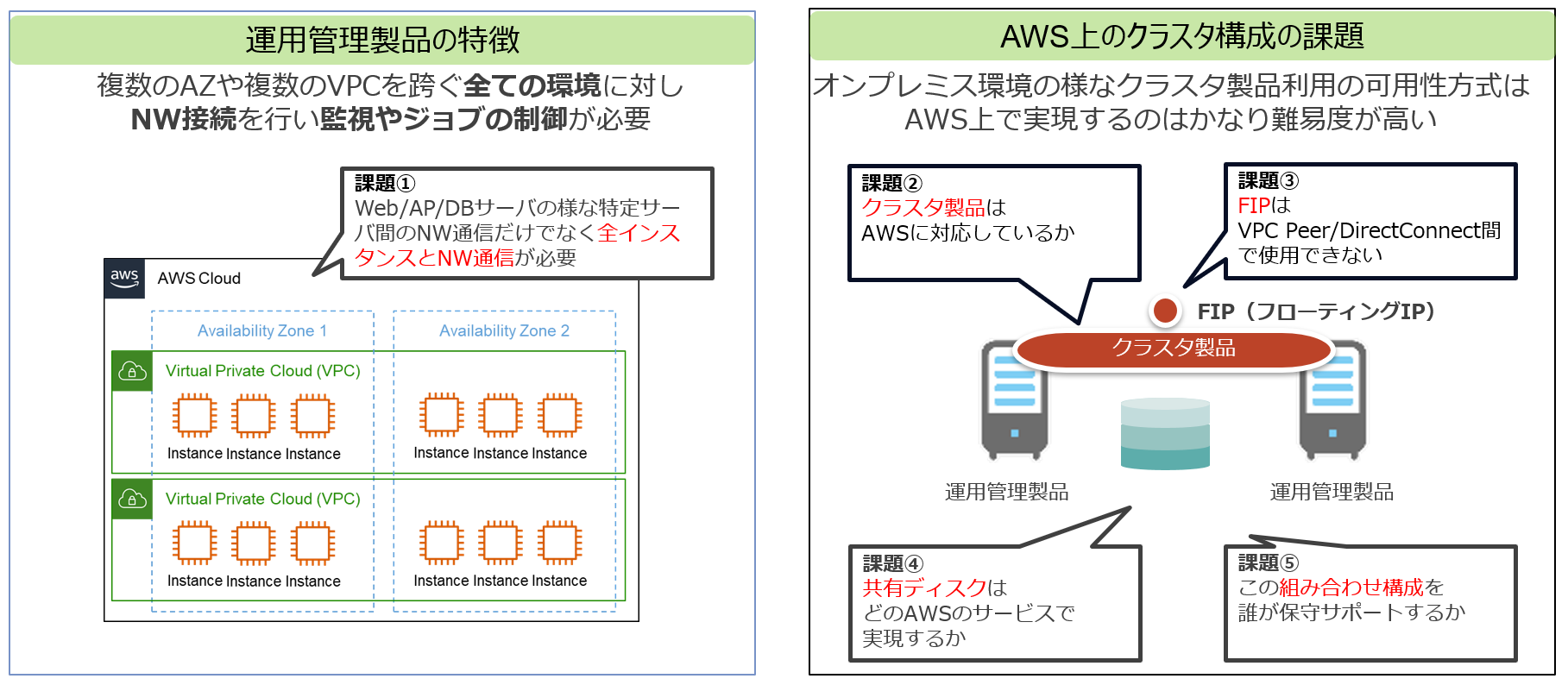
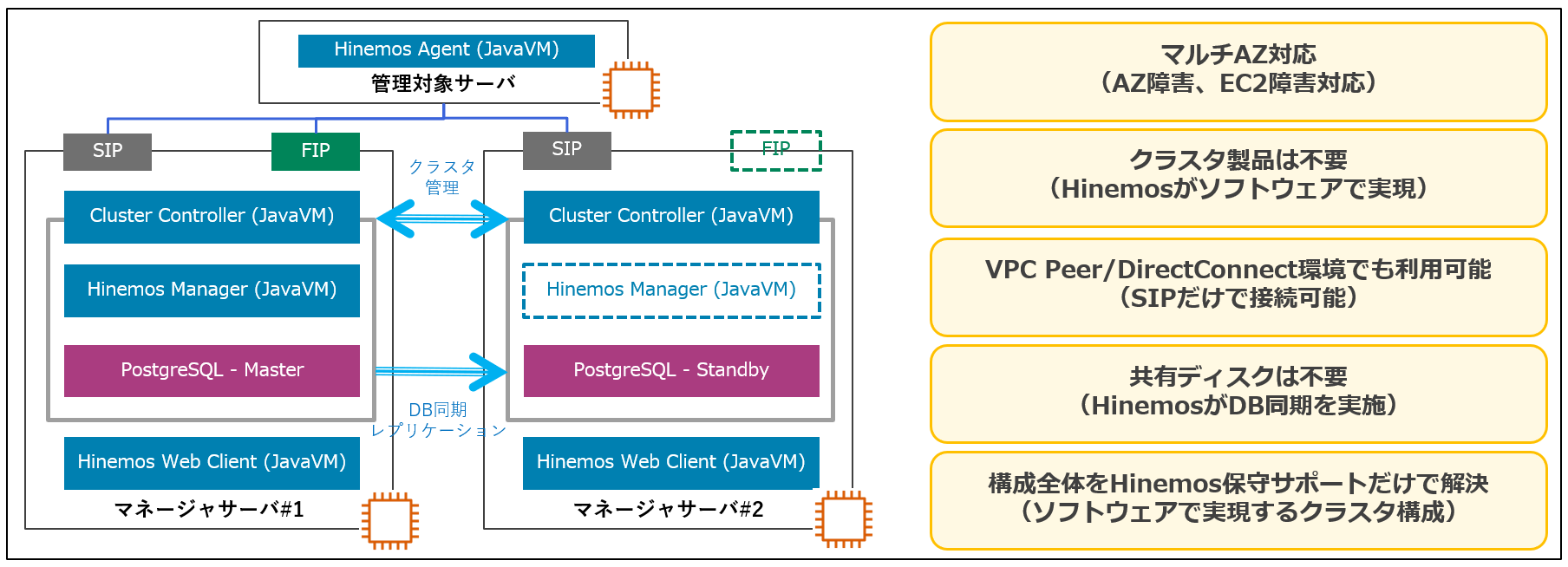
AWSにおけるHinemosの冗長化
Hinemos自身の冗長化は、Hinemosミッションクリティカル機能で実現しますが、その仕組みは非常にユニークです。古典的なクラスタ構成ではなく、Hinemosというソフトウェアで可用性を実現しています。そのため、先ほどの課題は全て問題とはならず、EC2インスタンス2台を用意するだけで監視・ジョブ管理の高可用性構成が可能になります。
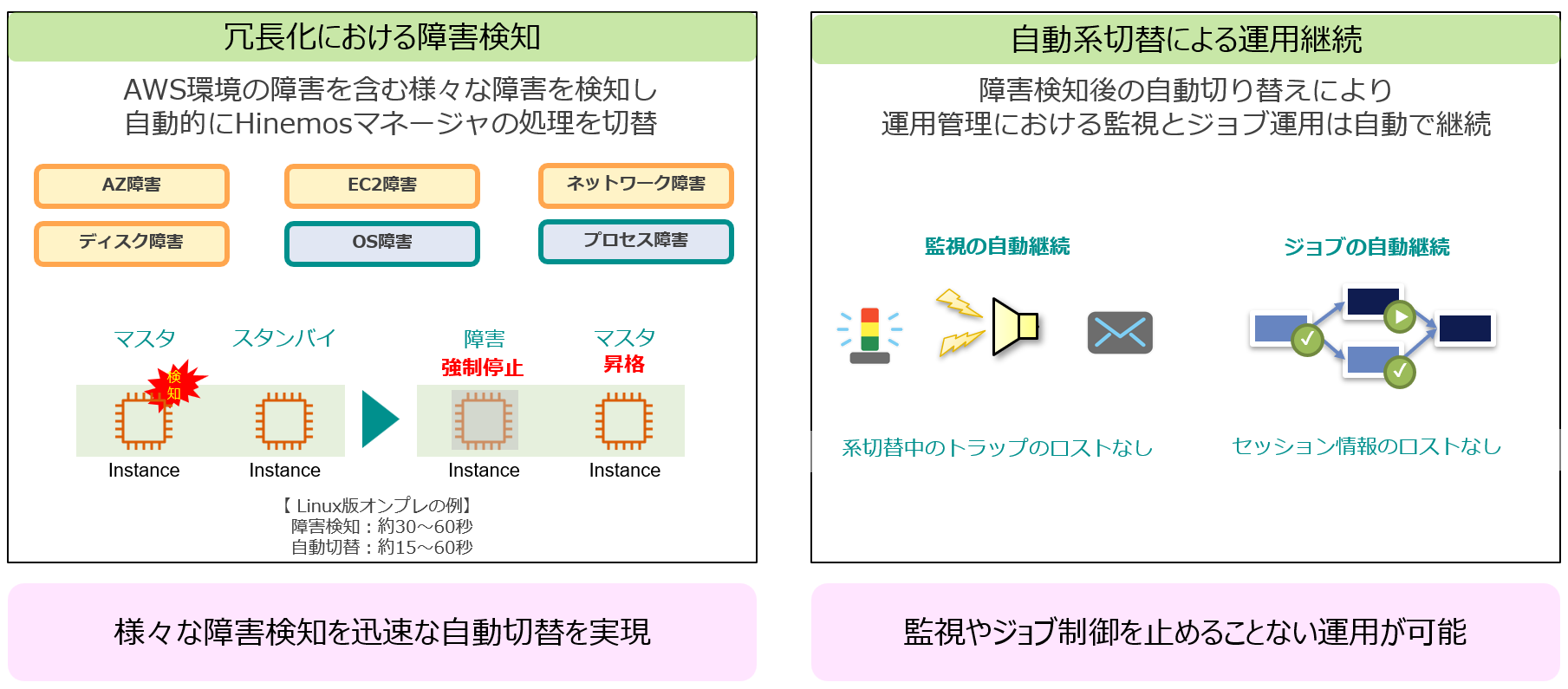
Hinemosの冗長化における障害検知と自動系切替による運用継続
Hinemosミッションクリティカル機能では、AWSのEC2やAZの障害発生時にも迅速にHinemosマネージャをマスタからスタンバイに自動切替し監視やジョブ制御の自動継続を実現します。
技術解説
AWSにおけるHinemosの冗長化の特長
ソフトウェアだけで可用性構成を実現するHinemosミッションクリティカル機能には、重要な6つの技術的特長があります。クラスタ製品を必要とする古典的な可用性構成と比較しながらHinemosミッションクリティカル機能の6つの技術的特長を1つずつ解説します。
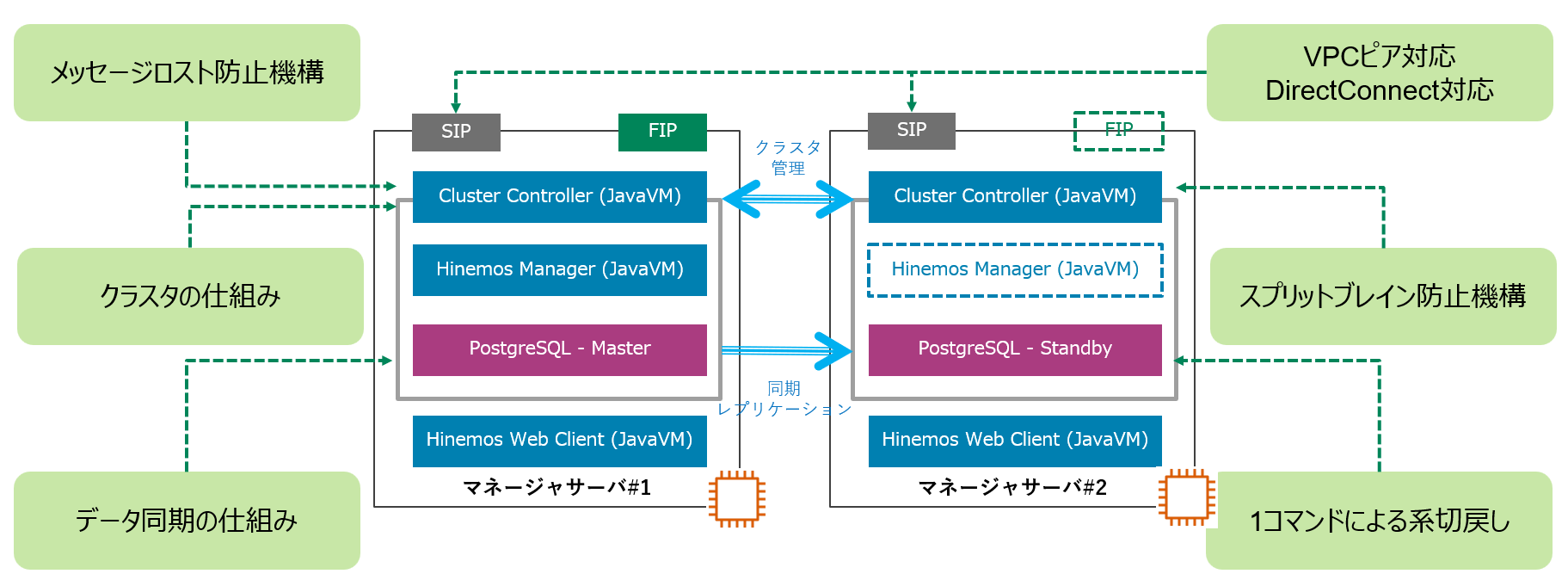
-
特長① クラスタの仕組み
古典的なクラスタ構成では別途クラスタ製品の購入が必要です。そのため、複数の製品とサービスが入り乱れる複雑な仕組みになります。
代わって、Hinemosはクラスタ制御をソフトウェア(Cluster Controller)で実現します。ソフトウェアとしてクラスタ制御を行いHinemosの世界だけで冗長化が可能となっています。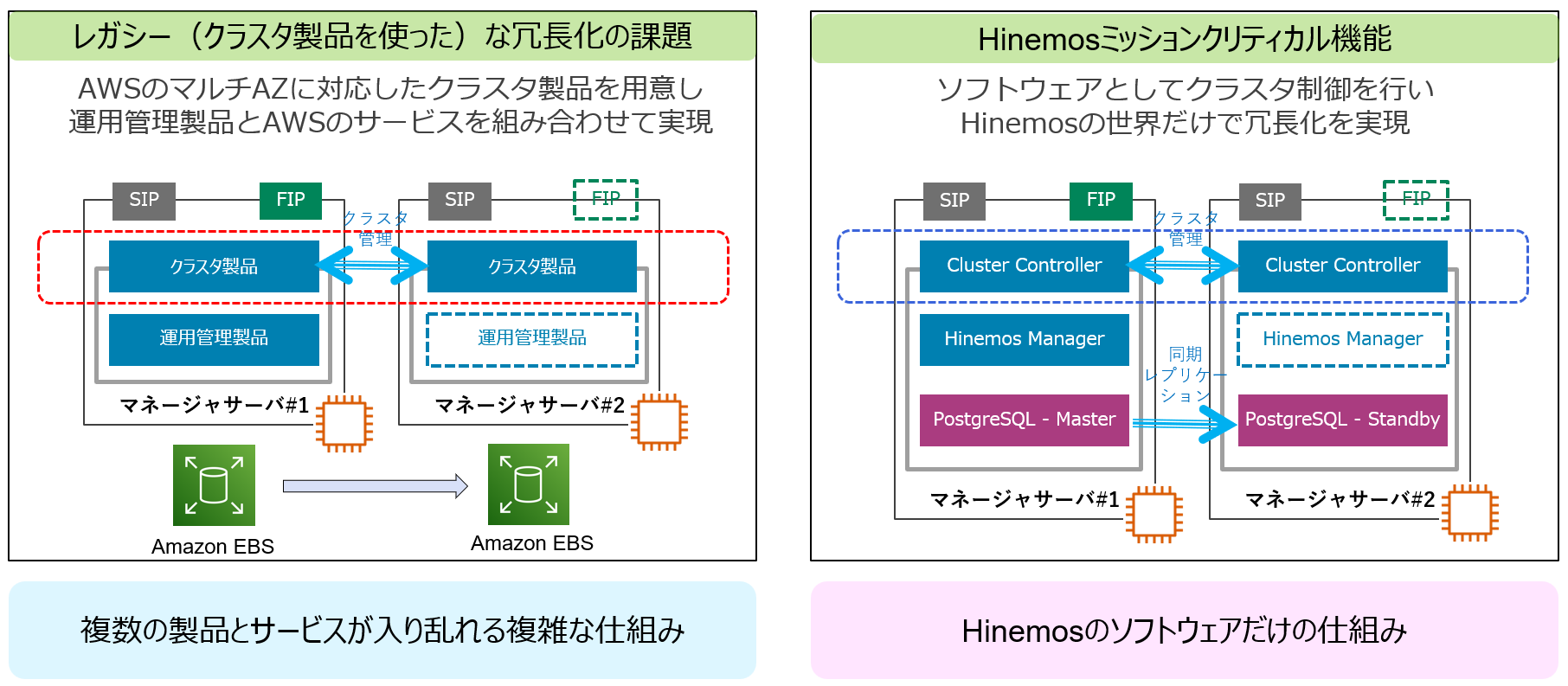
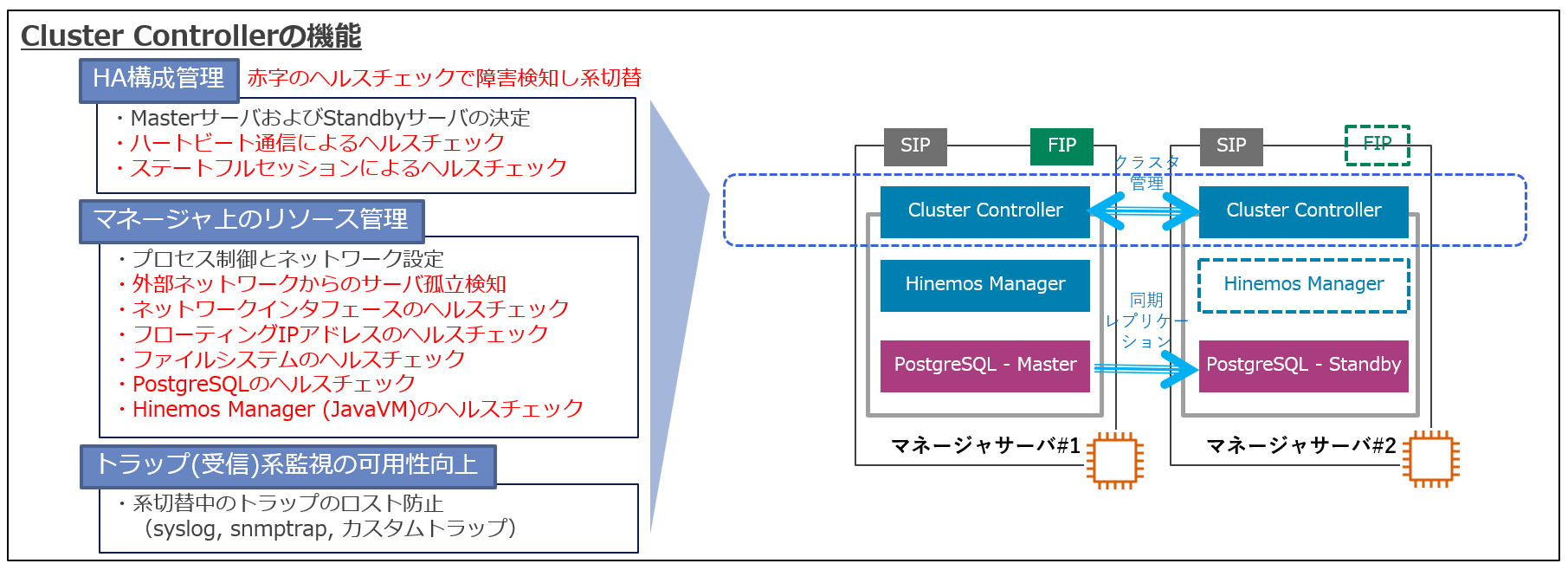
Cluster Controllerは次の様なクラスタ制御の機能を担い、系切替が必要な障害の検知と可用性を維持しています。
- - HA構成管理
- - マネージャ上のリソース管理
- - トラップ(受信)系監視の可用性向上
-
特長② データ同期の仕組み
運用管理製品の多くは内部データベースを保持します。ジョブ管理におけるジョブの定義から実行履歴であったり、監視の設定や結果などの情報を安全に管理します。古典的なクラスタ構成では、この内部データベースを共有ディスクに配置します。しかし、AWS上ではこの共有ディスクの部分をどうやって実現するかも課題になり、例えばデータ同期をAWSのクラウドサービスに頼る仕組みを用いたりする必要も出てきます。
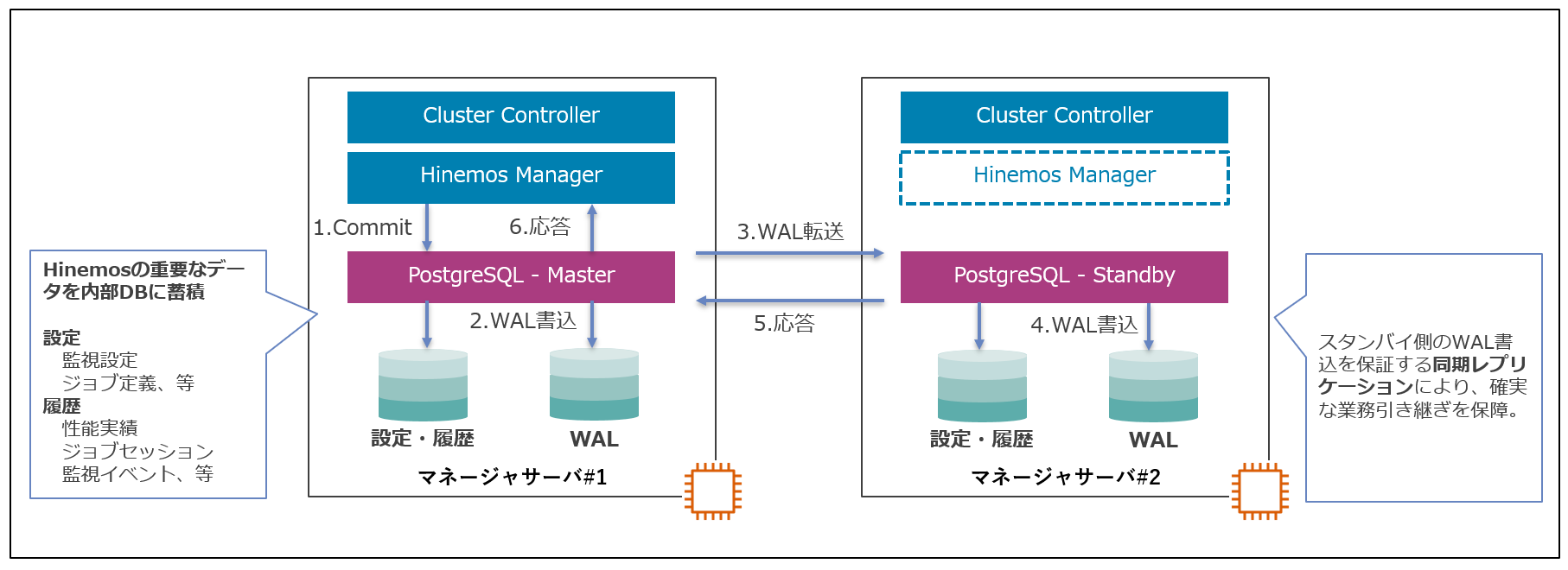
代わって、Hinemosはデータ同期を内部DBであるPostgreSQLの同期レプリケーションで実現します。Hinemosの内部DBが同期レプリケーションを行いHinemosの世界だけで冗長化を実現します。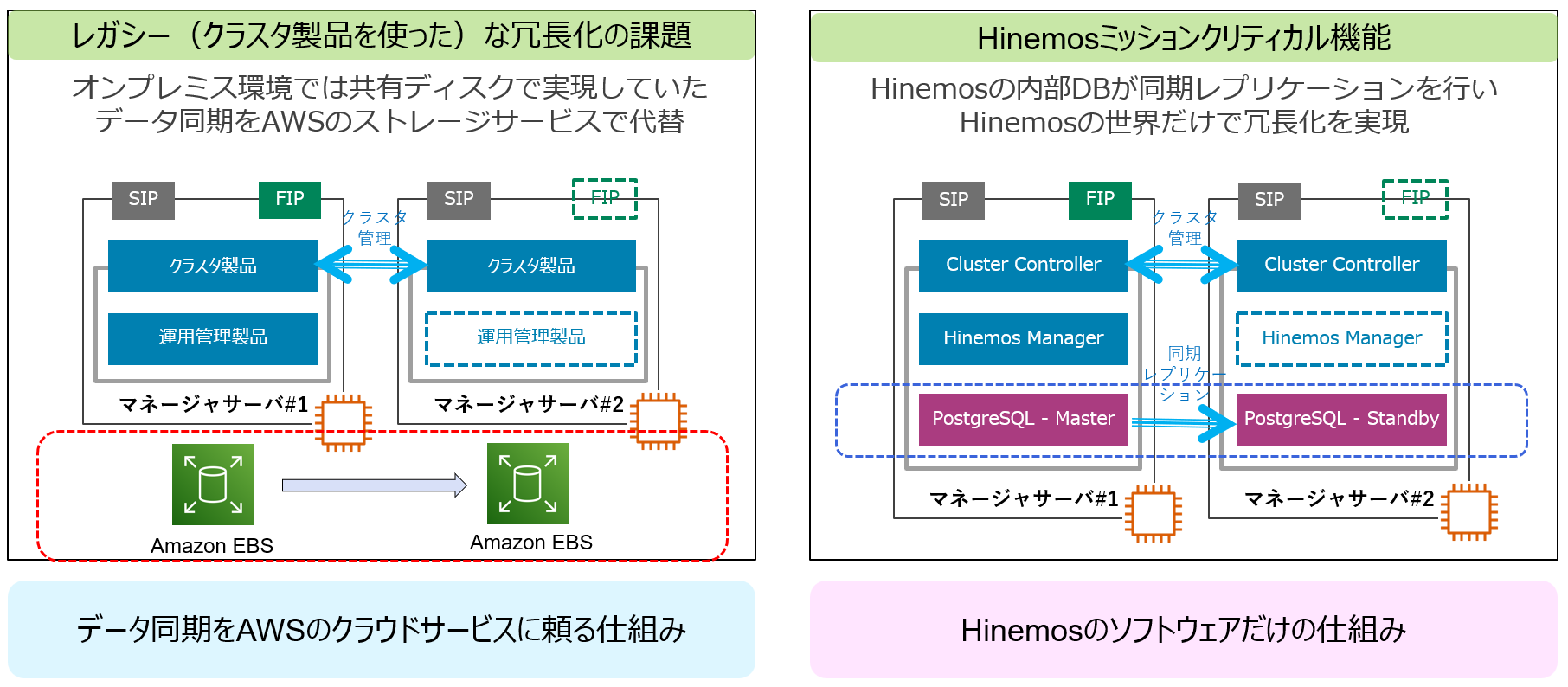
Hinemosの設定・履歴情報を蓄積する内部データベースはPostgreSQLを採用しており、この内部データベースのデータ同期をPostgreSQLの同期レプリケーション機能で実現しています。
-
特長③ VPCピア対応/DirectConnect対応
古典的なクラスタ構成では、エージェント–マネージャ間はFIPで通信するためVPCピアやDirectConnectを跨いで使用できないという課題があります。運用管理のマネージャがクラスタ構成において系切替時にFIPも同時に切替ても、そもそもエージェント側が接続できないのです。そのため、VPC間を跨ぐ構成にも様々な試行錯誤が必要な仕組みになります。
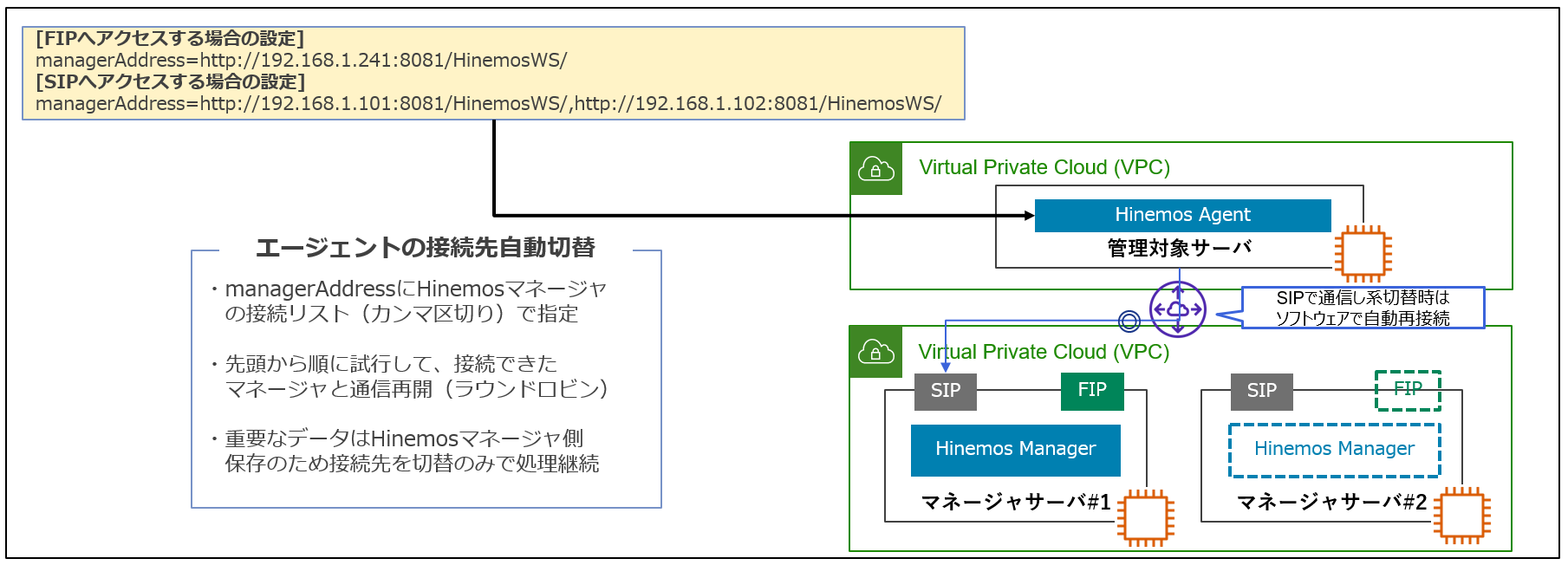
代わって、Hinemosは固定IP(Static IP;以降、SIP)しか使えない環境でもエージェント - マネージャ間の通信が可能です。そのため、VPCピアやDirectConnectを跨いだ環境でも安心してご利用いただけます。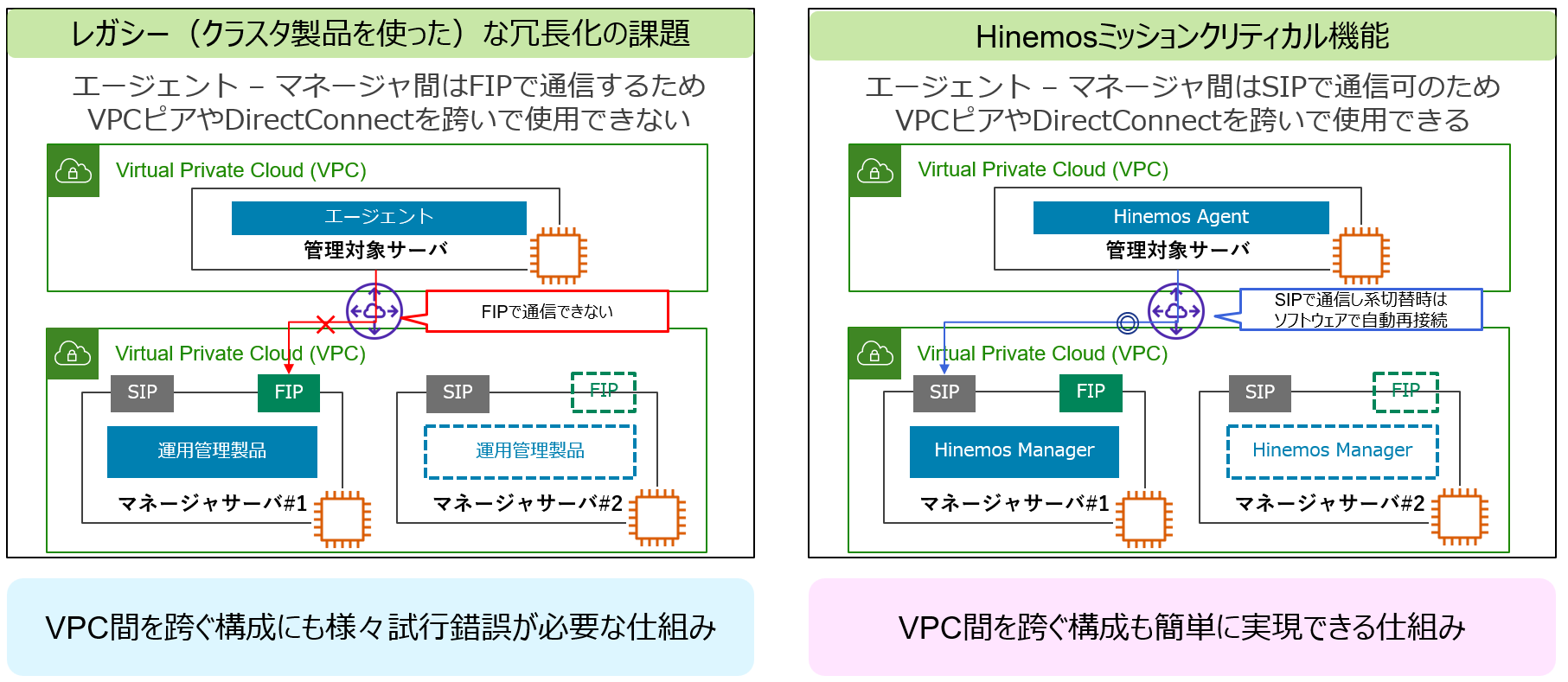
Hinemosエージェントは、シンプルな接続方式にてHinemosマネージャのFIP/SIPの両方に対応にしています。Hinemosエージェントに、Hinemosマネージャのマスター(#1)とスタンバイ(#2)の両方の接続先を設定に記入しておくと、接続できる方に順次接続しに行きます。これによって、FIPが使用できないVPCピアやDirectConnect環境下でも、可用性構成を簡単に実現できます。
-
特長④ メッセージロスト防止機構
古典的なクラスタ構成では運用管理マネージャが障害で系切替中は、トラップとして送信されたメッセージはロストします。そのため、系切替中に大事な監視のイベントを取り損なう可能性があります。
代わって、Hinemosはsyslogやsnmptrapの様なトラップ型のメッセージを系切替中もロスト無しで監視できます。これは先に説明したCluster Controllerの機能によって実現しています。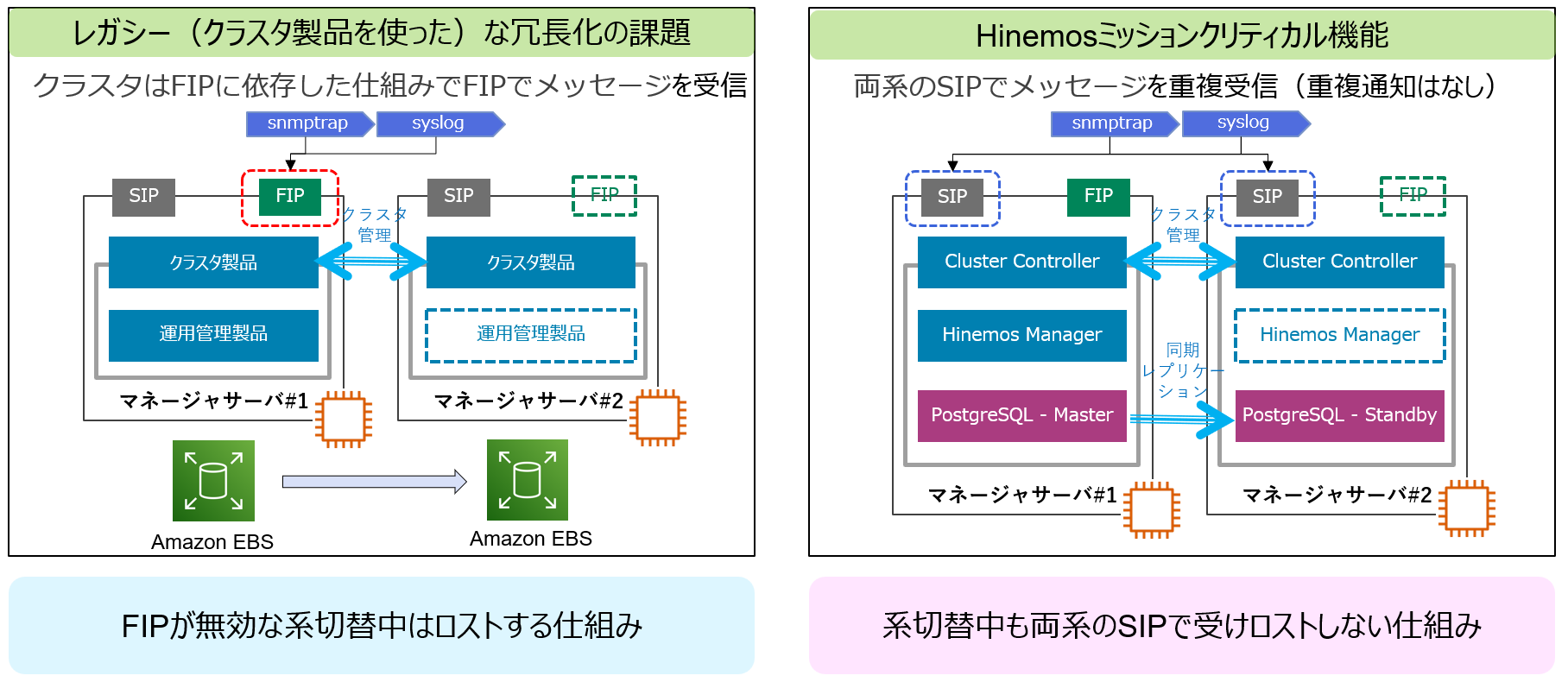
Cluster ControllerがHinemosマネージャのマスタ(#1)とスタンバイ(#2)の両系でトラップ型データを重複受信して、系切替中のデータロストを防止しながら重複通知を抑制しています。重複受信しているからといって、同一のトラップ(イベント)が複数検知されることはありません。このように、クラスタ製品を使った冗長化方式では実現の難しい系切替中のデータロスト防止に対応しています。
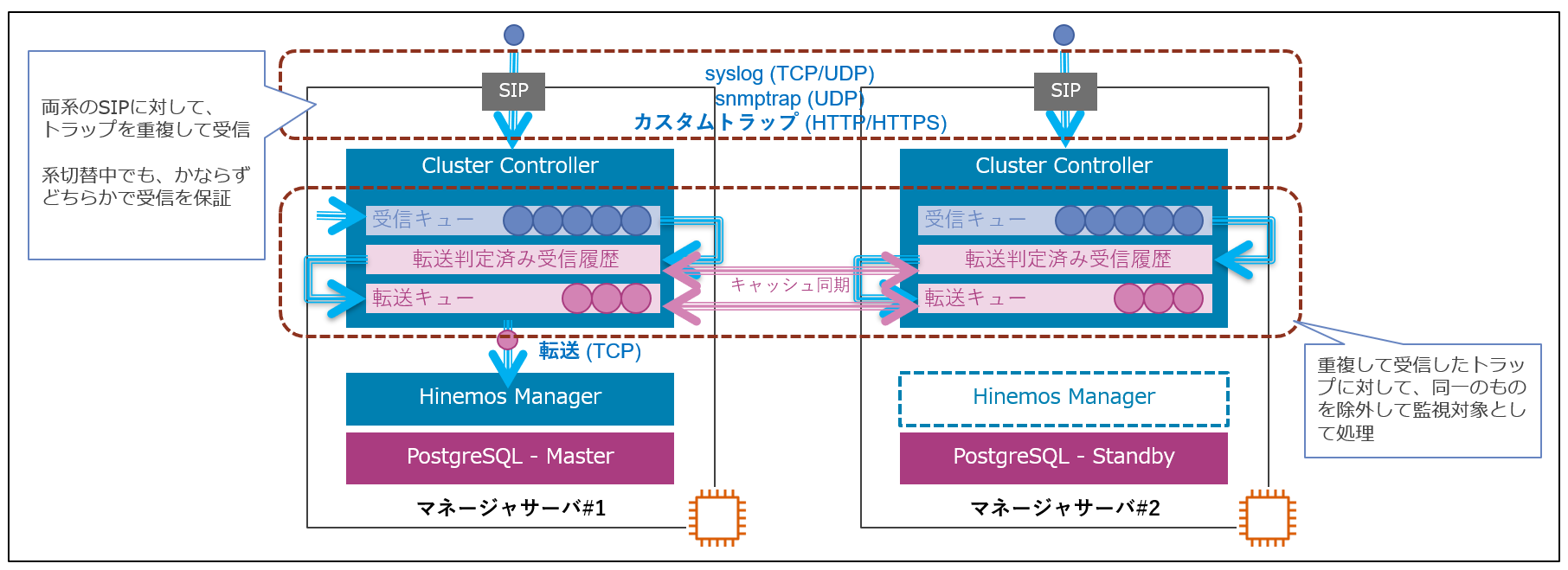
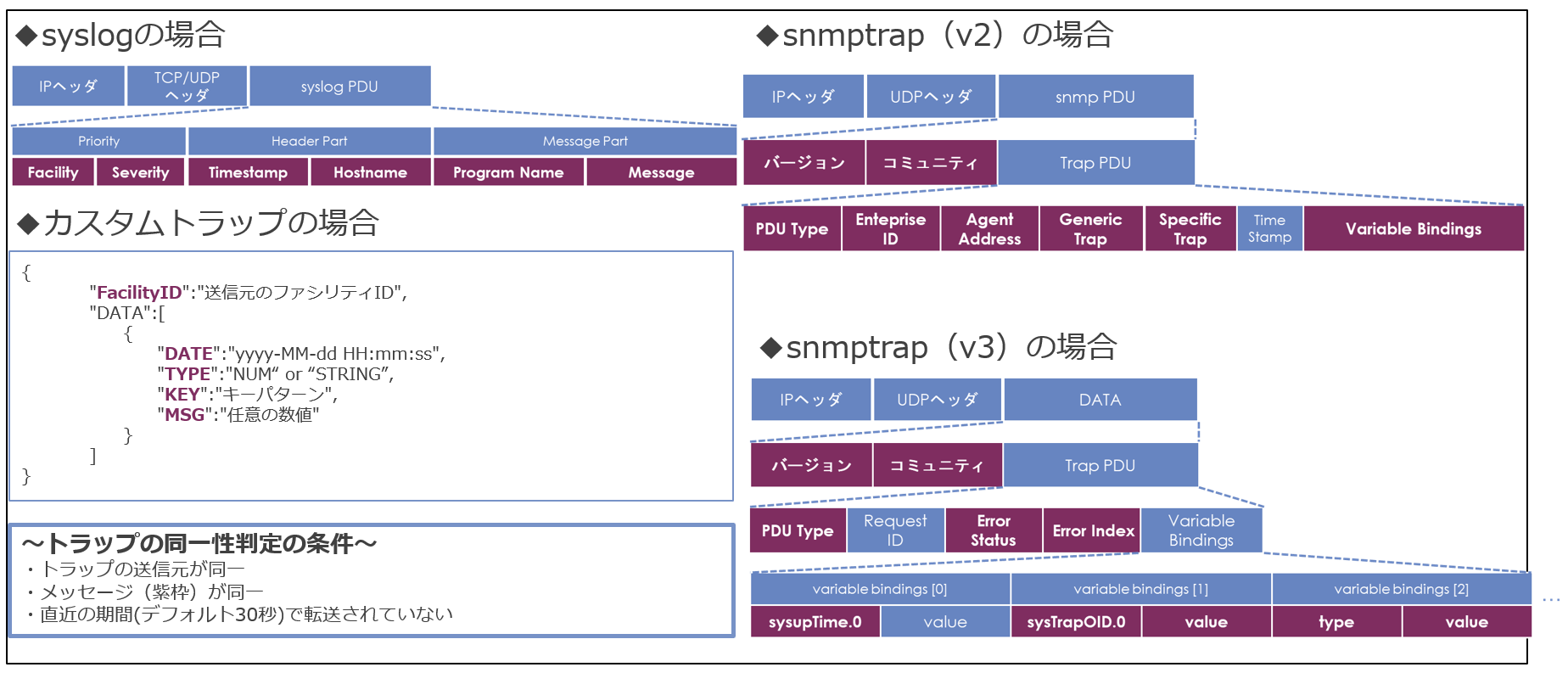
少し細かいですがsyslogやSNMPTRAPなど各トラップは、以下の様なメッセージの内容をベースに同一性判定を処理します。
-
特長⑤ 1コマンドによる系切戻し
古典的なクラスタ構成では、運用管理製品、クラスタ製品、共有ディスクがセットのため、障害パターンによって対処を検討する必要があります。何か障害が発生して運用管理マネージャが両系から片系になったあと、再び両系に復旧(系切戻し)する際も同様です。
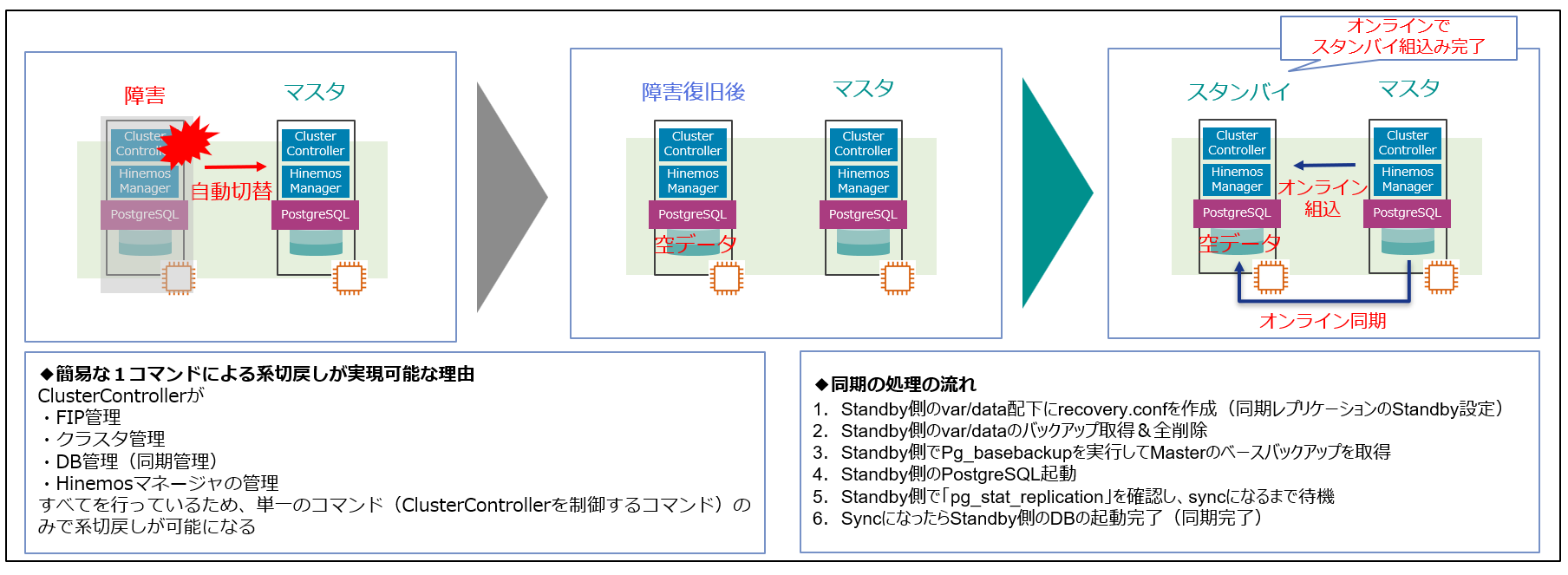
代わって、Hinemosの系切戻し(片系から両系への復旧)は簡単な1コマンドのオンライン操作で実現できます。ソフトウェア制御によりEC2のみで完結する構成のため系切り戻しは1パターンの1コマンドのみとなり、手順の実施ミスのようなことは起こりえません。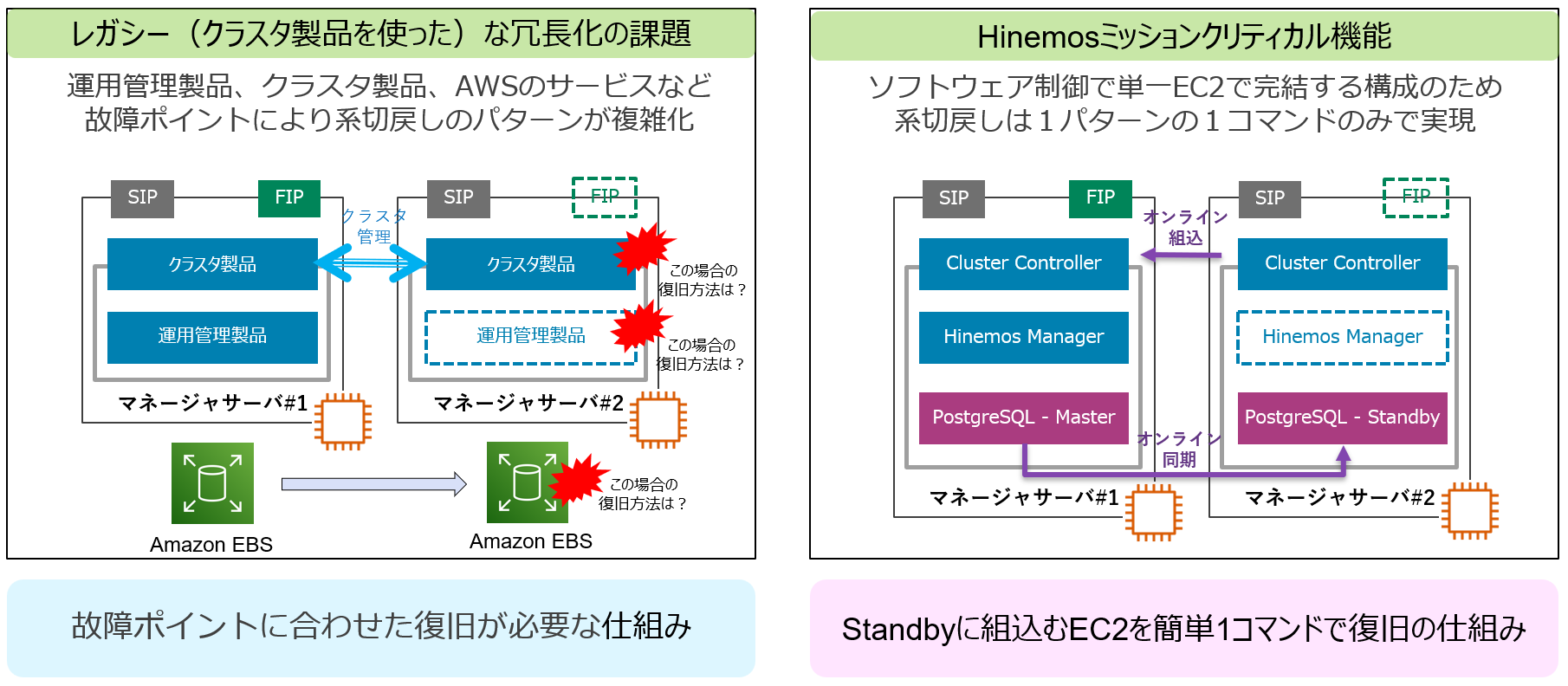
Hinemosのソフトウェアの制御による切戻しのイメージは以下の通りです。故障ポイントによって切戻しパターンを変えることなく安全安心の操作でオンライン系切戻しを実現します。
-
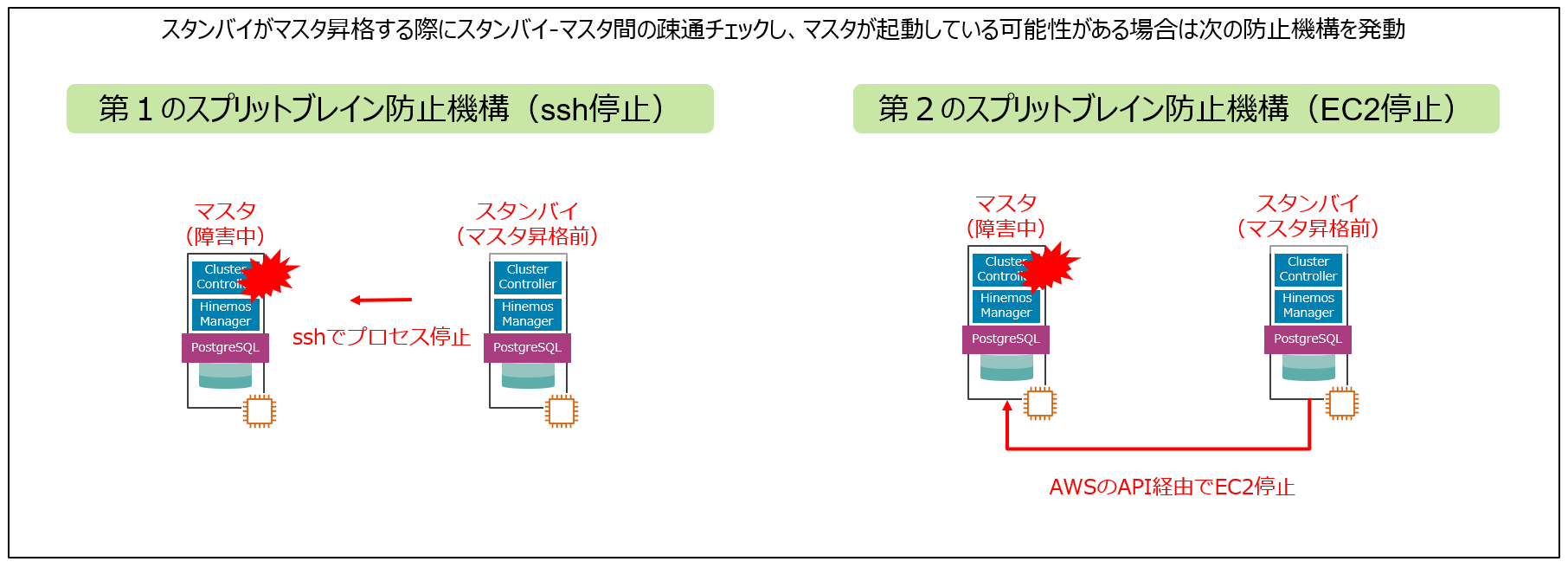
特長⑥ スプリットブレイン防止機構
最後の特長として、Hinemosのスプリットブレイン防止機構を説明します。スプリットブレインとは複数のマスタが存在する危険な状態を指します。これに対し、Hinemosは二重のスプリットブレイン防止機構を完備しています。ソフトウェア制御するHinemosにより安心のクラスタ管理を実現します。
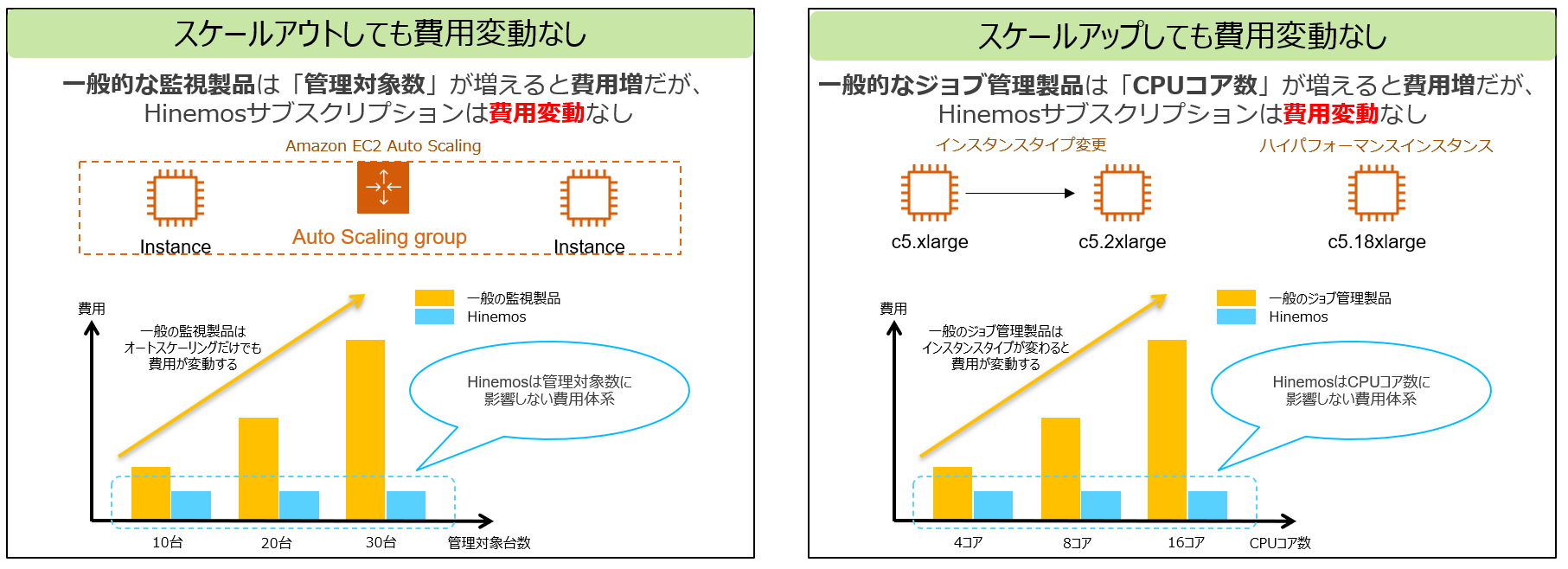
費用体系
クラウドに最適なライセンス体系
Hinemosの可用性構成の動作解説と少しずれますが、Hinemosはクラウドに最適なライセンス体系のHinemosサブスクリプションというメニューで提供しています。このHinemosサブスクリプションは、Hinemosマネージャのインストール数(ユニット数)で費用が決定します。つまり、Hinemosは運用管理製品の費用を気にすることなく、クラウドのメリットであるEC2のスケールアウト・スケールアップの活用が可能です。
AWSにおけるHinemosの冗長化方式の優位性
これまで解説してきたAWSにおけるHinemosの冗長化方式の優位性を纏めてみます。ソフトウェアで可用性を実現するHinemosは、レガシーな冗長化方式の運用管理製品より以下の様々な点でメリットがあると言えます。
| Hinemosミッションクリティカル機能 | レガシー(クラスタ製品を採用する) な冗長化方式 |
|||
|---|---|---|---|---|
| 動作要件 | ◎ | AWS対応 / ネットワーク制約なし | ✖ | 製品によりAWS非対応 / ネットワーク制約がある |
| 構築 | ◎ | ソフトウェアのインストールのみ | ✖ | ソフト、サービスを組み合わせたセットアップ |
| 切替時間 | ◎ | 素早い切替(1~2分) | △ | 数分~数十分かかるものも |
| 監視 | ◎ | トラップ型監視のロスト防止機構 | ✖ | トラップ型監視はロスト |
| ジョブ | ◎ | ジョブ制御の自動継続 | ◎ | ジョブ制御の自動継続 |
| 復旧 | ◎ | 1つの復旧コマンド | ✖ | 障害パターンごとの復旧方法 |
| 保守性 | ◎ | ワンストップ保守サポート | ✖ | 障害ポイントごとに異なる保守サポート |
| 費用(全般) | ◎ | Hinemosのソフトウェア費用のみ | △ | クラスタミドル、ストレージサービスの費用が追加 |
| 柔軟性 | ◎ | ライセンス費用がスケールアウト / アップを阻害しない | ✖ | ライセンス費用がスケールアウト / アップを阻害する |
お問い合わせ
AWSにおけるHinemosの冗長化方式の優位性についてご理解頂けたと思います。AWS環境の運用管理にお困りの方、Hinemosにご興味のある方は、ぜひお問合せ下さい。
- - オンプレからAWSに移行する際の運用管理に悩まれている方
- - AWS上の監視やジョブの可用性に課題をお持ちの方
- - AWSの特徴を生かしたシステムの運用管理を簡単に行いたい方

お問い合わせ内容の記載例
-
お問い合わせ対象
記事:AWSにおけるHinemosミッションクリティカル機能
-
お問い合わせ内容
AWS環境の運用管理の課題やご相談事項、または、Hinemosミッションクリティカル機能について詳しくお知りになりたい内容をご記入ください。
まとめ
AWSにおけるHinemos冗長化のベストプラクティスとして、次の内容をお伝えしました。
- - AWS上で運用管理製品の可用性を実現する事はかなり難しいこと
- - Hinemosはソフトウェアで可用性構成を実現していること
- - Hinemosの可用性構成は6つの技術的な特長があること
- - Hinemosはクラウドに最適なライセンス体系であり、スケールアウト/アップが気兼ねなく出来ること
ぜひ、AWS上の運用管理にはHinemosの導入をご検討ください。
